上一篇介紹所抓取內容是直接從網頁原始碼就可以取得,但如果是Ajax或動態網頁,
很多時候要你要直接用get()是抓不到的,這種情況就要想辦法用動態載入把內容抓出來。
本篇所要教大家使用Selenium載入Ajax生成的頁面結果並抓取資料。
#事前準備
- python2.7
- package:Selenium
- 爬取網站:http://soccerdata.sports.qq.com/fixture/23.htm
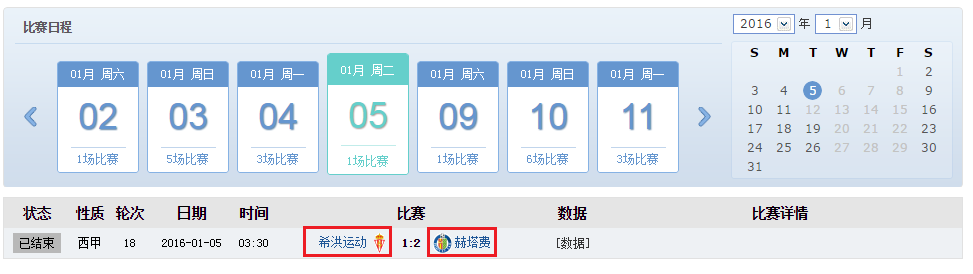
- 爬取內容:抓取每場比賽之隊伍連結,EX:抓2016/1/05 用紅框框起來的西甲球隊網址,如下圖
- 這部份程式碼會較上一篇困難許多,有興趣可以去網頁熟悉一下控制鍵,而下面的程式碼就是要模擬並實作你click的這些按鍵
#程式碼
#-*-coding: utf-8 -*-
from selenium import selenium
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.keys import Keys
import time
import codecs
from BeautifulSoup import BeautifulSoup
from datetime import date
from datetime import datetime
#==============================Step 1
list_url=[]
days=input("Enter the day number:")
browser=webdriver.Firefox()
browser.get('http://soccerdata.sports.qq.com/fixture/23.htm')
soup=BeautifulSoup(browser.page_source)
for d in range(1,days+1):
m1 = soup.findAll('td',{'class':'t_right'})
m2 = soup.findAll('td',{'class':'t_left'})
m3 =soup.findAll('tbody')
for i in range(1,len(soup.findAll('tr'))):
m4=m3[0].findAll('tr')
game_time=m4[i].findAll('td')[3].text.strip("\r\n")
home_team_href=str([tag['href'] for tag in m1[i-1].findAll('a',{'href':True})])[3:-2]
away_team_href=str([tag['href'] for tag in m2[i-1].findAll('a',{'href':True})])[3:-2]
home_team_url="http://soccerdata.sports.qq.com"+str(home_team_href)
away_team_url="http://soccerdata.sports.qq.com"+str(away_team_href)
list_url.append(home_team_url)
list_url.append(away_team_url)
file_ = codecs.open(game_time+".txt","w",'utf-8')
for url in list_url:
file_.write(url+"\r\n")
list_url=[]
#==============================Step 2
if d%7==0:
browser.find_element_by_xpath("//ul[@id='li_scroll']/li[4]/p[2]").click()
soup=BeautifulSoup(browser.page_source)
if d%7==1:
browser.find_element_by_xpath("//ul[@id='li_scroll']/li[3]/p[2]").click()
soup=BeautifulSoup(browser.page_source)
if d%7==2:
browser.find_element_by_xpath("//ul[@id='li_scroll']/li[2]/p[2]").click()
soup=BeautifulSoup(browser.page_source)
if d%7==3:
browser.find_element_by_css_selector("p.schedule-riqi").click()
soup=BeautifulSoup(browser.page_source)
if d%7==4:
browser.find_element_by_css_selector("span.jian_1").click()
browser.find_element_by_xpath("//ul[@id='li_scroll']/li[7]/p[2]").click()
soup=BeautifulSoup(browser.page_source)
if d%7==5:
browser.find_element_by_xpath("//ul[@id='li_scroll']/li[6]/p[2]").click()
soup=BeautifulSoup(browser.page_source)
if d%7==6:
browser.find_element_by_xpath("//ul[@id='li_scroll']/li[5]/p[2]").click()
soup=BeautifulSoup(browser.page_source)
file_.close()
browser.close()
程式碼有點攏長,我會分成兩部份來說明
Step1:
1-6行程式碼:
- 會開啟FireFox瀏覽器並get()你所輸入之網址,並套入BeautifulSoup做Regular expression
- days部份是控制我要爬取多少天的比賽(後面會再提到)
7-9行程式碼:
- 這邊的迴圈就是要決定你要抓幾天的比賽
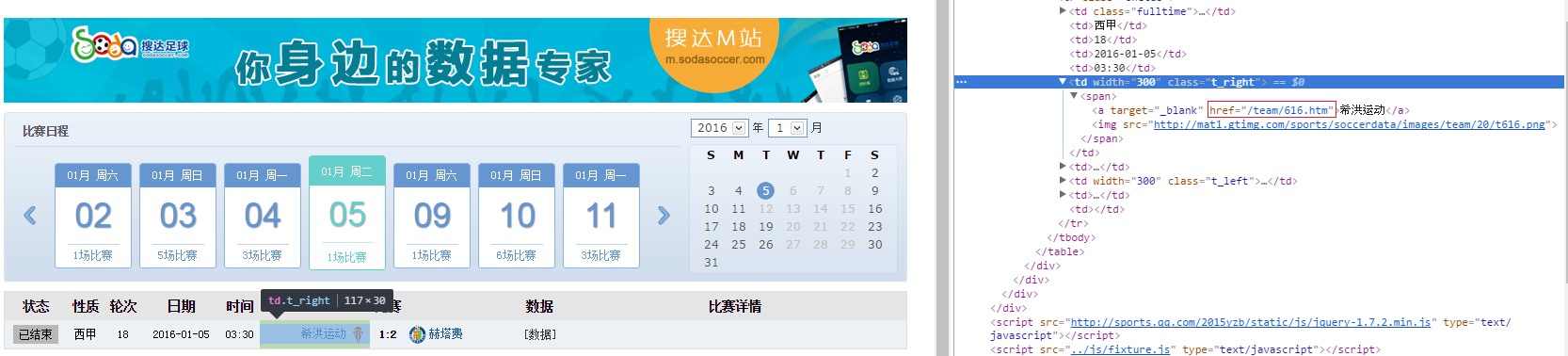
- 用findAll抓取主客的框架,藍色區塊是主場框架(class="t_right"),客場就是(class="t_left"),如下圖
10~程式碼:
- 我們要抓的herf再<a>裡面,因此home_team_href與away_team_href抓取了主客場連結
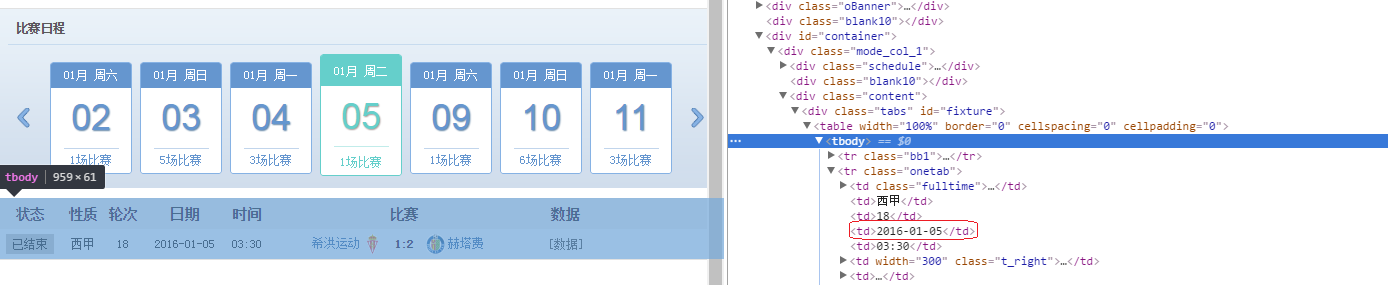
- 我想用game_time作為我的文字檔檔名,因此也抓比賽時間,如下圖
- 把網域名稱:"http://soccerdata.sports.qq.com"加上我們抓取的herf就是我們想要的資料
- 最後就是把抓好的資料放入list存入.txt
Step2:
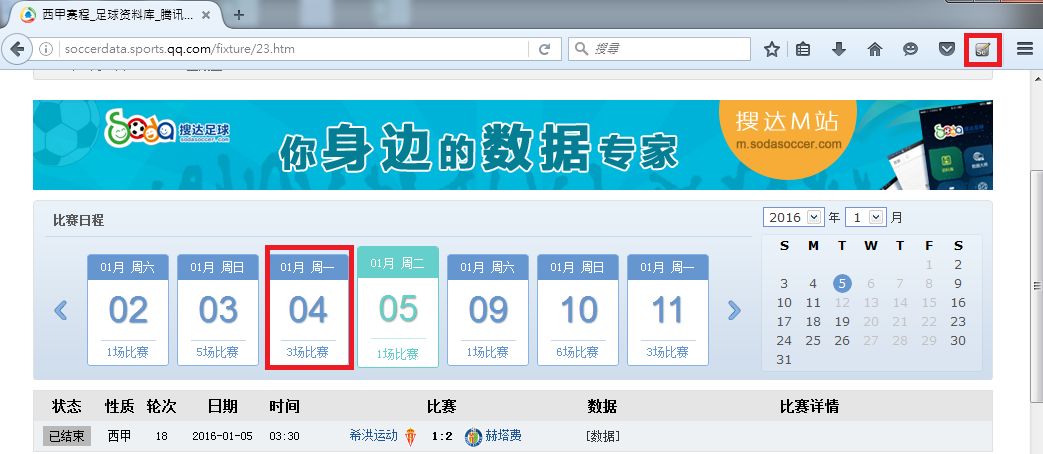
步驟1其實還是圍繞上一篇所說的方法,而我們如果要抓1/5號以前的比賽就要去點擊前一場控制鍵框架,且你會發現當轉換到1/4號時,頁面網址並不會轉換,所以像遇到這樣問題可以用selenium來解決。
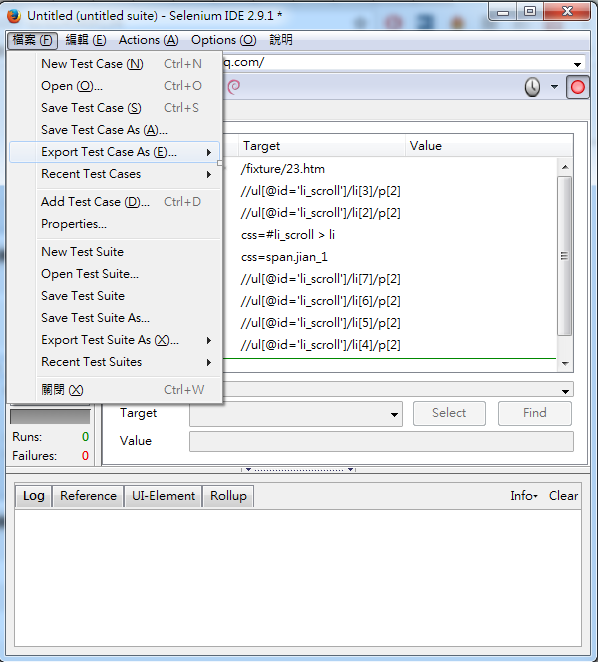
首先,我們要先再FireFox安裝一個工具selenium IDE(在google搜尋下載即可),裝好後,就會顯示在遊覽器上面,如上圖右上角,而右下角紅色框就是我們要找的控制項。
我們打開selenium IDE,並開始點擊控制鍵,模擬一次直到重復為止,如下圖我們照順序來按,這順序剛好為一輪且不重複。


而我們使用的selenium IDE會呈現如下圖,且我們把他存成python檔,打開後我們就可以得到我們想要的控制項程式碼。
 接下來就是很簡單的餘數關係啦(看起來很簡單,但當初也想了一段時間XD),用一開始所輸入的天數除以7
接下來就是很簡單的餘數關係啦(看起來很簡單,但當初也想了一段時間XD),用一開始所輸入的天數除以7
對應的餘數就是我要去執行的控制項,執行完就是用BeautifulSoup做Regular expression,就可以順利抓到所有資料拉。