識別圖片中的文字的應用,包含Line App交談對話框中,選擇圖片後,點選[A]符號即可偵測文字。
另外目前已普遍運在停車車牌辨識、證件辨識上。
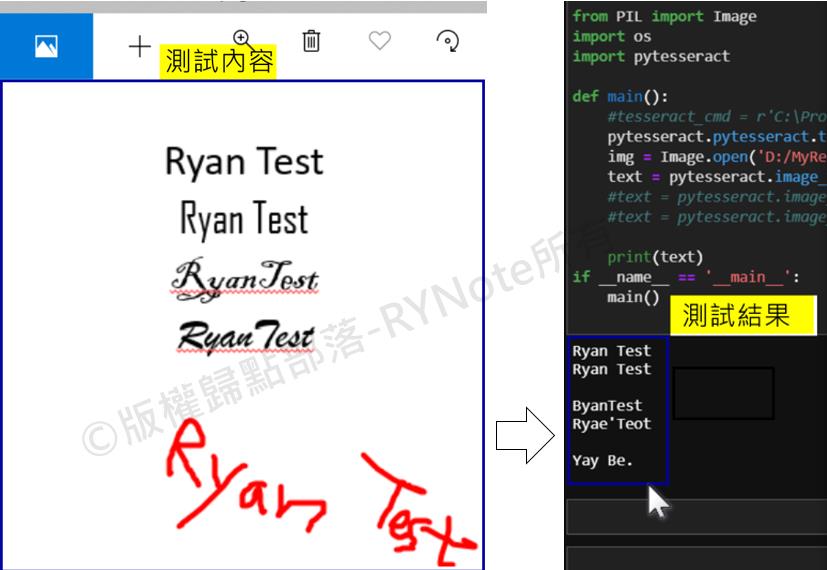
不論是手寫,或者電腦打字,不受排版的影響,
且將圖片轉換成文字或數字後,有個好處,可以進行搜尋。
實現此應用的技術,叫做光學字元辨識(Optical Character Recognition,OCR),
Tesseract[ˈtɛsəˌrækt] 是光學字元辨識的模組之一。
使用Python pytesseract模組,達到光學字元辨識也相當簡單,僅幾步驟。
1.安裝pytesseract、pillow
pip install pillow
pip install pytesseract
2.下載Tesseract執行檔,並安裝至指定路徑(p.s.需要記得自己的安裝位置,後續會用到)
在安裝後,會發現Tesseract-OCR\tessdata的目錄下,只會有英文版的eng.traineddata
3.若需要支援簡體中文或繁體中文辨識,則需要另外下載chi_sim.traindata、chi_tra.traineddata字庫。
完整的語言包位置: https://github.com/tesseract-ocr/tessdata
下載後,放於Tesseract-OCR\tessdata的目錄下。
若連結失效也可以直接 Google "chi_tra.traineddata" "chi_sim.traindata"
4.程式碼
from PIL import Image
import pytesseract
def main():
pytesseract.pytesseract.tesseract_cmd = r'XXXXXX\Tesseract-OCR\tesseract.exe'
#指定tesseract.exe執行檔位置
img = Image.open('XXXXXXXX/XXXX.png') #圖片檔案位置
text = pytesseract.image_to_string(img, lang='eng') #讀英文
#text = pytesseract.image_to_string(img, lang='chi_sim') #簡體中文
#text = pytesseract.image_to_string(img, lang='chi_tra') #繁體中文
if __name__ == '__main__':
main()
同時也歡迎追蹤Tableau Public Gallery- MR.360 |聚沙成塔,裡面包含文章中的案例實作,
期待能帶給您新的啟發或靈感。
未來文章將喬遷新址「一趟數據分析之旅」,歡迎追蹤繼續支持,您將不會錯過任何新知識。