Reference:https://github.com/bubbliiiing/yolov4-pytorch
Key Word:WSL2、Bubbliiiing、Pytorch YOLOv4、Object Detection、RTX4060、Github License Issue、Roboflow、CrowdHuman
前言
AI 物件偵測在各家公司實務應用上一直是個很重要的研究議題,不管是內部提升作業效率,或者是包裝在自家的產品中成為模組的一部分,達到販售功能的目的。
普遍大家最常做的事情也就是上 Github 找看看有沒有好用的 Project 可以依據場景練出自己的模型。而在商用的考量下,通常使用的 Github Project License 最好要是 Apache-2.0 或是 MIT 之類可商用的規範,避免日後遇到整個系統程式碼因使用較強規範的 GPL/AGPL license project 導致需要公開原始碼的窘境。YOLO 通常是大家最常用的物件偵測模型,也是比較容易上手的(當然如果要完全弄清楚裡面的架構和 Augment Trick 又是另一件事情),但之前公司內的前輩千交代萬叮嚀,如果要使用 YOLO,要注意 YOLOv5 開始的 license 基本上都是 GPL 以上。同時我也稍微看了 v4 和 v5 的一些別人的評價,發現 v5 並不是官方認證的版本,據說是創新性不足且演算法不夠進化… (https://pedin024.medium.com/%E5%88%9D%E6%8E%A2yolov5-71f13b4ba78d)。
基於上述原因,決定以 YOLO 最新可商用版本 v4 進行實作 (我知道 Bubbliiiing 還有另一個 YOLOX 的版本 https://github.com/bubbliiiing/yolox-pytorch,但目前有測出問題無法解決 https://github.com/bubbliiiing/yolox-pytorch/issues/121,原版 YOLOX 也有一樣的問題 https://github.com/Megvii-BaseDetection/YOLOX/issues/1161,有的人解的了有的人解不了,剛好我就是用盡辦法解不掉的那個),google 了一下發現 2020 年左右陸續有 Pytorch 版的 YOLOv4 被實作出來,稍微踩坑 Survey 了其中 3 個作者提供的 Github Project (Bubbliiiing、WongKinYiu、Tianxiaomo),統整如下表:
| 作者 | Github project URL | License | 是否支援負樣本訓練 |
|---|---|---|---|
| Bubbliiiing | https://github.com/bubbliiiing/yolov4-pytorch | MIT | Y |
| WongKinYiu | https://github.com/WongKinYiu/PyTorch_YOLOv4 | AGPL 3.0 | Y |
| Tianxiaomo | https://github.com/Tianxiaomo/pytorch-YOLOv4 | Apache-2.0 | N |
我一開始用的是 WongKinYiu 的版本,確實可練,練出來的模型推論表現也非常的優秀(不愧是 YOLOv4 作者之一),但發現他的 Github 上並沒有標明 License,最後在 Issue List 裡面發現有人問他 License 是什麼,他的回覆是 AGPL (https://github.com/WongKinYiu/PyTorch_YOLOv4/issues/2),代表不能隨便商用。
搜尋其他的 Pytorch YOLOv4,你會發現搜尋榜上第一名的 Project 叫做 Tianxiaomo,我也確實把 Docker 環境弄出來可以訓練,但看起來在負樣本的處理上有問題 (我用自己的資料集丟進去練確實有報錯),後續在 Issue List 上也確實看到很多人在問關於負樣本的訓練有問題 (https://github.com/Tianxiaomo/pytorch-YOLOv4/issues/261、https://github.com/Tianxiaomo/pytorch-YOLOv4/issues/457),意即如果要訓練有負樣本的資料集,要進去看懂並調整程式才能練。而且看起來有其他人使用這個 Github Project 踩了很大的坑,怨念挺深的…(https://cloud.tencent.com/developer/article/2543275)。
Bubbliiiing 的 Github Project,你在 Google 上面用關鍵字 "Pytorch Yolov4" 是搜尋不到他的 Github 頁面的,後來是在某些 CSDN 網頁上知道他的 Pytorch Yolov4 URL 後,用 Bubbliiiing 這個關鍵字再去找才獲得更多資訊,把訓練與推論的 Docker 環境建出來後使用,認為這是個相對穩健的版本,且 Code 裡面的註解非常清楚,Bubbliiiing 本人也有拍很多教學影片在 Bilibili 上,是個兼具教學與實用性於一身的 Github Project,本篇技術網誌將會以這個 Project 實作,訓練出一個行人物件偵測模型。

一. 資料準備
行人偵測最著名的就是用 CrowdHuman 資料集 (https://www.crowdhuman.org/download.html),但是偏偏這個資料集註明 Research Only,代表拿去商用可能會出大事。
使用知名可商用的 COCO Dataset (https://cocodataset.org/#download) 或是 Open Image(https://storage.googleapis.com/openimages/web/download_v7.html) 取 Person 類別,會發現像這種 CCTV 視角的資料還真的不多,而且人過於密集無法標註時,會直接把整坨人框起來,表示不適合標註 (COCO, iscrowd=1) 或是群體標註 (Open Image, IsGroupOf=1),使用上必須要先將這些 BBox 拿掉避免模型學歪掉,不是很友善,你若將資料下載後用 Label Image 工具打開來看,就會看到像下圖的狀況。

我後來是直接在 universe.roboflow.com 上面用關鍵字 Crowd Human 找到許多好心人開源的資料集 (License CC By 4.0) 拿下來做使用,但其中不少資料集也是有上述問題 (多人標註一個 BBox),這部分就要挑一下,至少資料集是可商用的,且品質上也符合我要較多的 CCTV 視角。
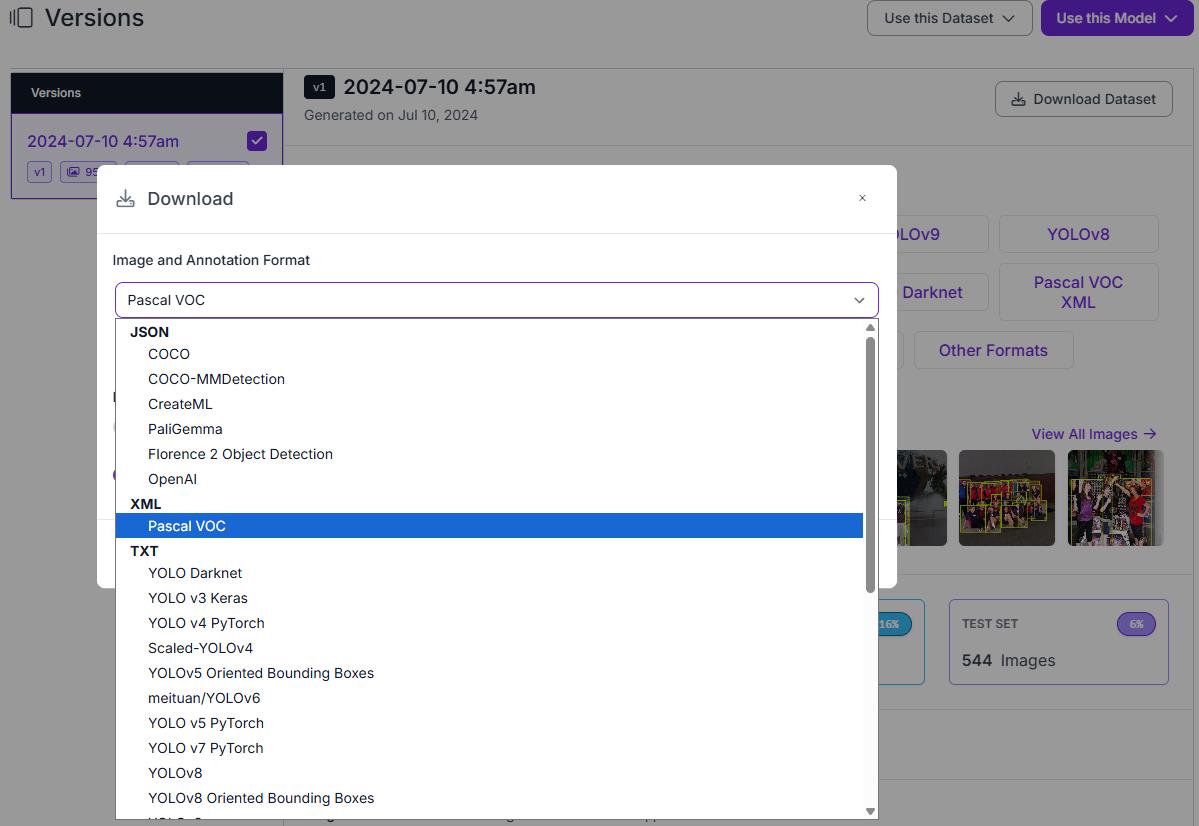
資料下載也很貼心,可以選各種不同的格式,我們使用的 Bubbliiiing 專案使用的是 VOC 格式,下載時請選擇 VOC,下載後你會發現圖片與標記檔都被放在同一個資料夾,在 Bubbliiiing Project 中,做好的 VOC 格式資料需要放在 VOCdevkit/VOC2007 資料夾下的 Annotations 和 JPEGImages 資料夾,因此我們將 xml 標記檔以及原圖分別放在在 Annotations 和 JPEGImages 資料夾,並產生一個內容僅有一行 Person 字眼的 cls_classes.txt 一同手動壓縮成一個 Roboflow_crowdHuman_voc.zip 檔備用。
二. 訓練 Docker 環境準備
提供我自己摸索出來確定可用的 Dockerfile 供大家使用,Image 基底使用的是 Ubuntu 22.04,較 Bubbliiiing 官方的 requiirements.txt 不同,調整部分 lib 版本和欠缺套件,並將 Pytorch 版本提高到 2.6。
有看過我之前寫的 Docker 環境文章的朋友應該會注意到我之前建立 Docker Image 的方式都是用下指令產生 Container 後再用 Docker Commit 產生 Image,這其實是玩 Github Project 初期需要先確認環境的方式(有些 Github 年久失修,requirements.txt 內容早已不能使用,只能自己除錯),我來發現每次重建都要下指令很麻煩,乾脆在解決環境問題後用 Dockerfile 寫好一次解決,也可以在跟別人解說時快速建立環境,而且從 Ubuntu 基礎 Image 開始裝,也會比作者提供的 Docker Image 環境來的乾淨,對玩 AI 來說必備技能。Dockerfile 中的 bubbliiiing_pytorch_yolov4_training 資料夾其實就是官方 Github Project 載下來後改掉名字,其裡面內容物與官方一致(Pytorch 升級到 2.6 後,有些語法需要調整,可以在訓練時依據跳出的訊息提示做修改)。
### bubbliiiing 訓練 Dockerfile
# Date: 2025.11.02
# Author: Ryuichi
# Title: Training bubbliiiing Pytorch YOLOv4 Model Demo Sample
# Github: https://github.com/bubbliiiing/yolov4-pytorch
#
# Use an official Python runtime as a parent image
# docker build --no-cache -t bubbliiiing_pytorch_yolov4_training:version1 .
# docker run -itd --gpus all --shm-size=12G --name bubbliiiing_pytorch_yolov4_training -m 32g bubbliiiing_pytorch_yolov4_training:version1 bash
FROM ubuntu:22.04
WORKDIR /bubbliiiing_pytorch_yolov4_training
COPY . .
RUN apt update && apt upgrade -y \
&& apt install zip -y \
&& apt install vim -y \
&& apt install python3-pip -y \
&& apt-get install wget -y \
&& apt-get install git -y \
&& apt-get install libgl1-mesa-glx -y \
&& apt install libglib2.0-0 -y \
&& echo 'set encoding=utf-8' >> /etc/vim/vimrc \
&& DEBIAN_FRONTEND=noninteractive apt-get install -yq tzdata \
&& TZ=Asia/Taipei \
&& ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone \
&& dpkg-reconfigure --frontend noninteractive tzdata \
&& pip install numpy==1.26.4 \
&& pip install tensorboard \
&& pip install opencv-python \
&& pip install pycocotools \
&& pip install scipy \
&& pip install PyYAML \
&& pip install tqdm \
&& pip install matplotlib \
&& pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu124 \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/* \
&& rm -rf ~/.cache三. 佈署訓練資料
有了訓練用的 Docker Image 後,可以使用我 Dockerfile 註解上寫的指令建立 Container,並將前面產出的 Roboflow_crowdHuman_voc.zip 複製到 Container 內 Github Project 資料夾進行準備解壓縮。
docker cp Roboflow_crowdHuman_voc.zip <container_id>:/bubbliiiing_pytorch_yolov4_training/VOCdevkit/VOC2007

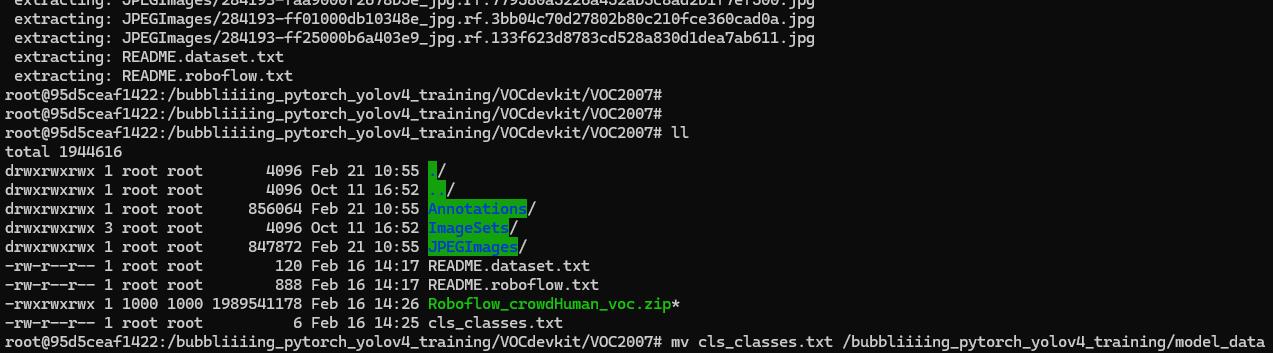
接著進入 Container 進行解壓縮,由於我們一開始就已經把圖片與標記的資料夾結構設定好,解壓時會直接解壓到對的資料夾中(/bubbliiiing_pytorch_yolov4_training/VOCdevkit/VOC2007 下的 Annotations 和 JPEGImages 資料夾),接著我們將 cls_classes.txt 移到 /bubbliiiing_pytorch_yolov4_training/model_data 下。
docker exec -it <container_id> bash
cd /bubbliiiing_pytorch_yolov4_training/VOCdevkit/VOC2007
unzip Roboflow_crowdHuman_voc.zip
mv cls_classes.txt /bubbliiiing_pytorch_yolov4_training/model_data
接著切回 /bubbliiiing_pytorch_yolov4_training 執行 voc.annotation.py 將資料轉換為 Bubbliiiing Github Project 的訓練資料格式,切分 training 與 valid 資料。
會產出 2007_train.txt 和 2007_val.txt 兩個指向檔案供訓練時讀取。
cd /bubbliiiing_pytorch_yolov4_training
python3 voc_annotation.py

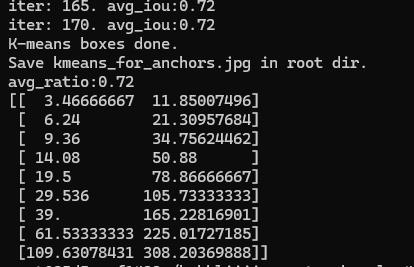
完成以上設定基本上就可以訓練模型了,但如果要更講究,基本上 YOLOv4 是 Anchor based,有先驗框的機制加快推理簡化後處理,預設的先驗框設定檔在 /bubbliiiing_pytorch_yolov4_training/model_data/yolo_anchors.txt,是使用 COCO Datasets 計算出來的,在訓練自己的資料集時不一定適用,可以使用 kmeans_for_anchors.py 來計算出適合自己 datasets 的 anchors。執行 python3 kmeans_for_anchors.py 後會產出 /bubbliiiing_pytorch_yolov4_training/yolo_anchors.txt,手動丟進去 model_data 資料夾中取代即可。

四. 修改 train.py 參數並撰寫多卡背景訓練 script
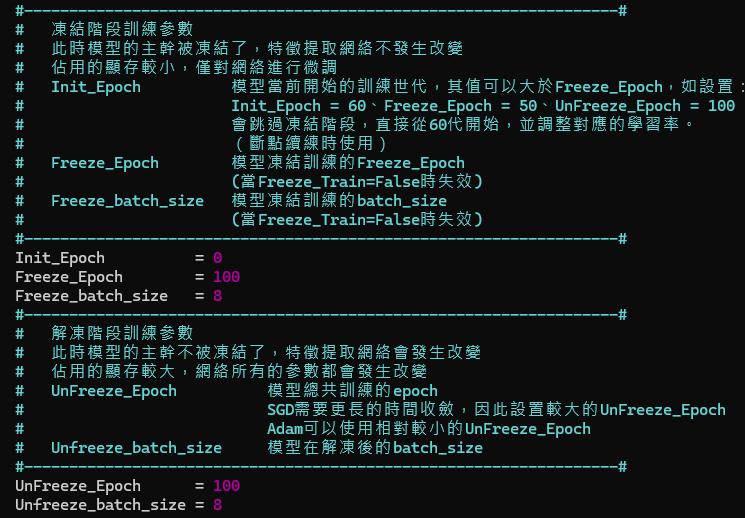
train.py 基本上撰寫了所有可以調的參數,作者在寫的時候有設計凍結參數的機制,你可以選擇要不要使用,註解都寫得很清楚了。
比較重要的是 mosaic 參數,畢竟我們想要應用的是 CCTV 視角,資料集內的資料人太大,有可能訓練出來到場景應用時人太小偵測不到,需要調整參數讓模型可以偵測到較小的物件,或是調整 input_shape 讓模型在學習時用較大的解析度學習,使其可以看到更多的特徵。
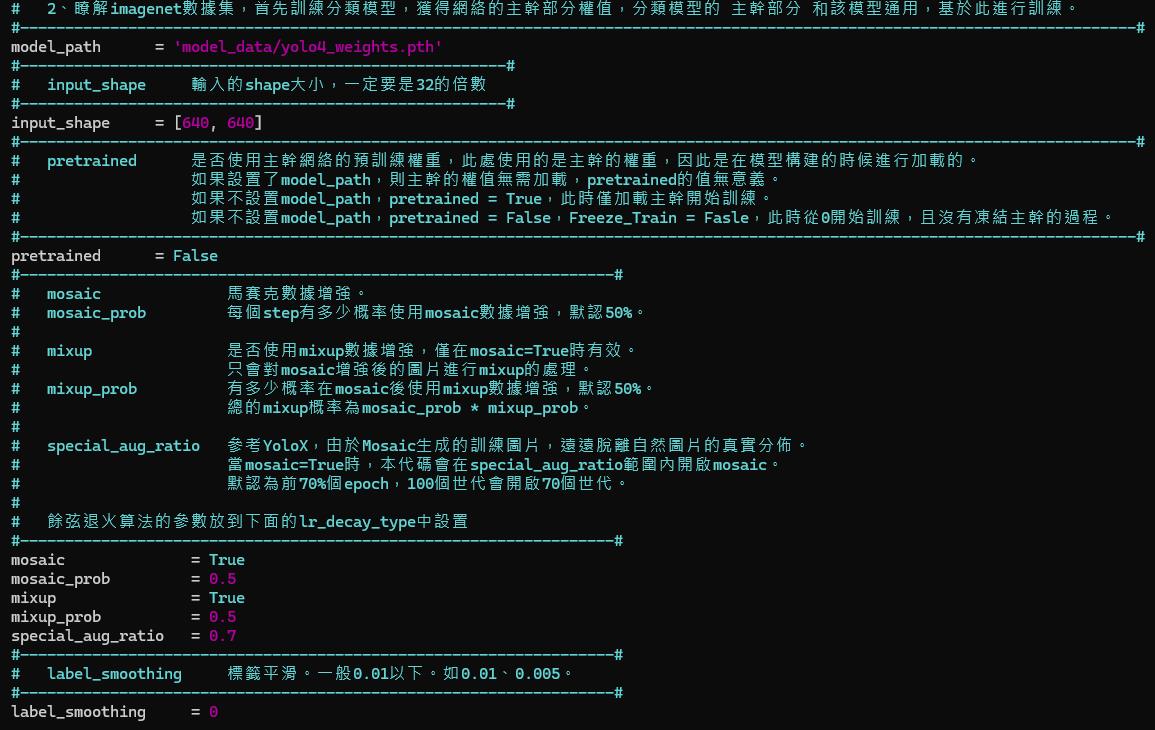
我通常會另外再寫一個 finetune.sh,用於設定顯卡編號以及觸發訓練,而且寫法會用分散式多卡的觸發方法,以利日後多卡訓練讓模型更穩定。

最後還會再寫一個 Nohup 的觸發 runNohupTrain.sh 讓執行訓練在背景執行。

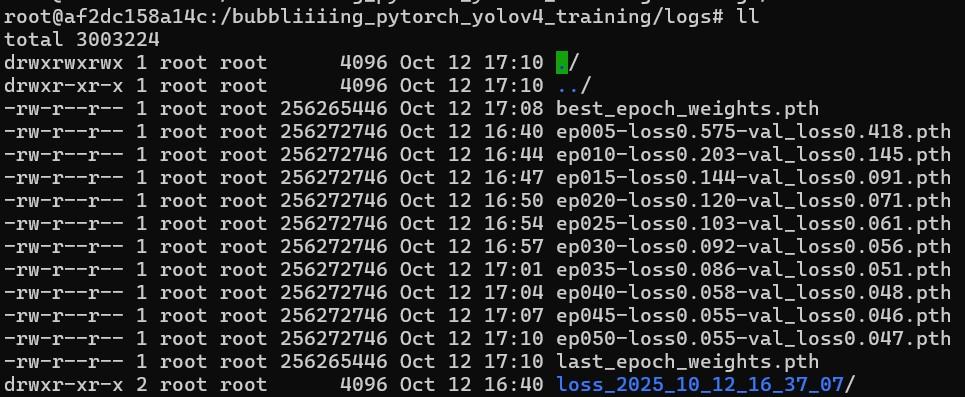
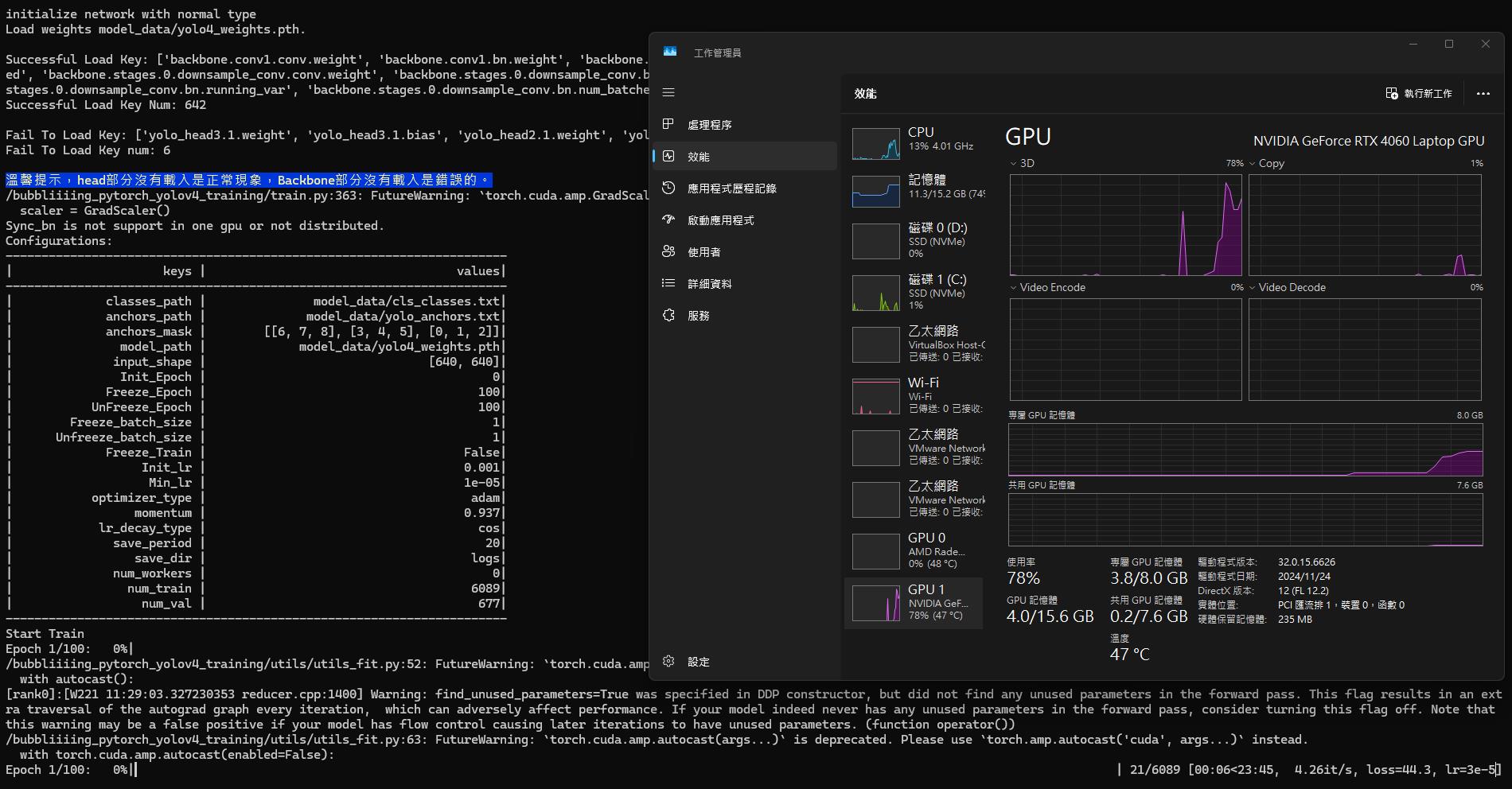
都設定好就可以送出去訓練了,這是用 RTX 4060 成功訓練的截圖,確定可以訓練後,便可將 Docker Image 拿到其他更強 Memory 更多的 GPU 上訓練讓模型更穩定。
五. 模型推論結果
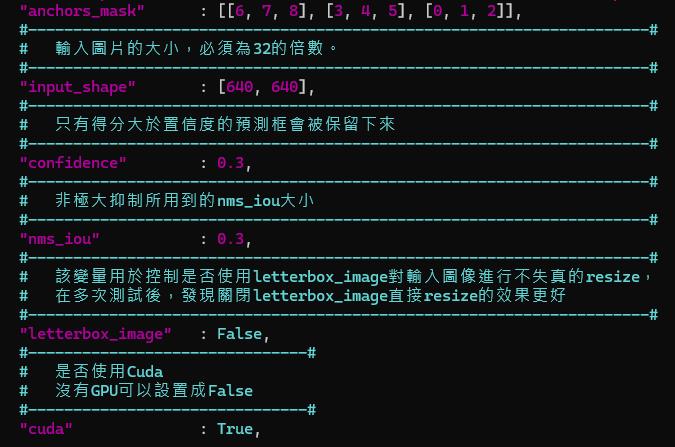
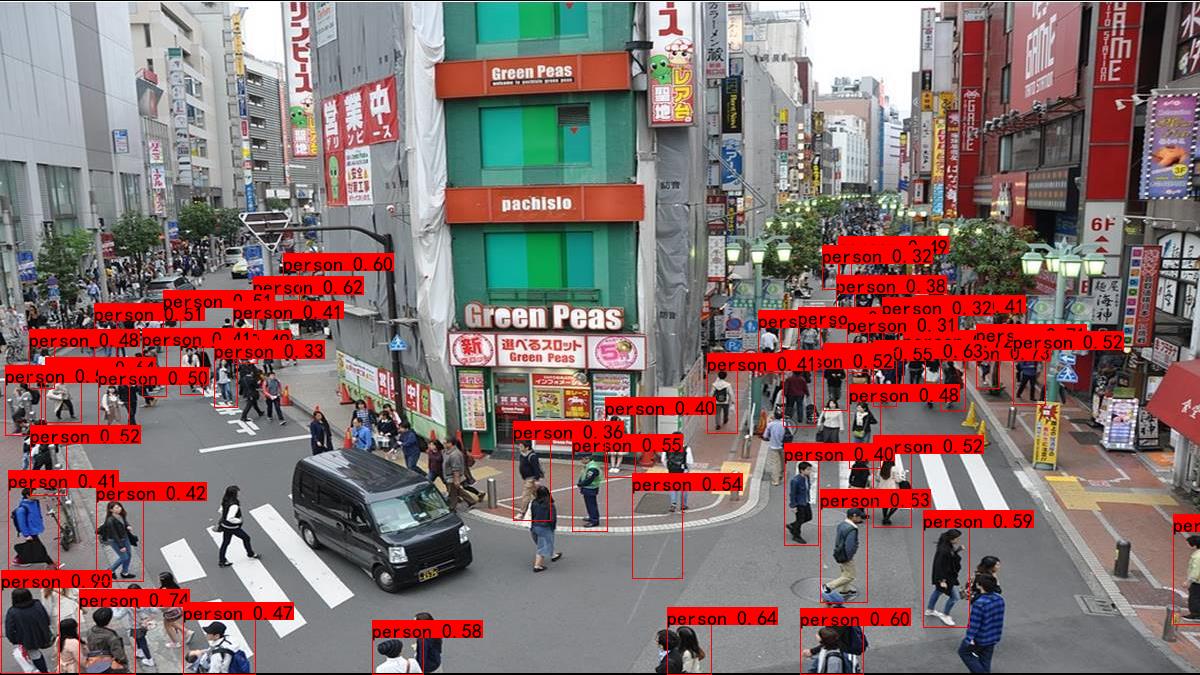
訓練好的模型可以在 /bubbliiiing_pytorch_yolov4_training/logs 中找到,從 https://www.pexels.com/video/people-walking-in-a-street-market-8301754/ 找個實際場景用既有的 predict.py 來驗一下,可以透過調整 yolo.py 的參數調整 confidence 以及其他設定值用於過濾。
結果看起來還需要一些空街道、空月台之類的圖片做負樣本讓模型學習,之後再找其他資料補足吧。