文、意如

MLD01.py
import numpy as np
input_file = 'wine.csv'
X = []
y = []
# TODO
from sklearn import model_selection
X_train, X_test, y_train, y_test =
from sklearn.tree import DecisionTreeClassifier
# TODO
# compute accuracy of the classifier計算分類器的精確度
accuracy =
print("Accuracy of the classifier =", , "%")
X_test1 =[[1.51, 1.73, 1.98, 20.15, 85, 2.2, 1.92, .32, 1.48, 2.94, 1, 3.57, 172]]
X_test2 = [[14.23, 1.71, 2.43, 15.6, 127, 2.8, 3.06, .28, 2.29, 5.64, 1.04, 3.92, 1065]]
X_test3 = [[13.71, 5.65, 2.45, 20.5, 95, 1.68, .61, .52, 1.06, 7.7, .64, 1.74, 720]]
# TODO
題目:
題號:101 紅酒種類預測
難易度:易
(一)、 題目說明:
下載ML00101.zip解壓縮後,請開啟MLD01.py依下列題意進行組合及改寫,再將求取之答案依序輸入填答視窗中。
請注意,資料夾或程式碼中所提供的檔案路徑,不可進行變動。
(二)、 設計說明:
請使用決策樹分類(Decision Tree Classifier),撰寫程式,讀取wine.csv,
這個資料集統計紅酒的品質資料,此資料集包含下列欄位:
欄位0(Target):紅酒的分類(總共分為3類,分別為1~3)
欄位1-13(Data):各種紅酒中各項化學成分檢驗結果,包含如:酒精、蘋果酸、鎂、黃酮、顏色強度、色澤…等等。
請將75%的資料做為訓練資料集,25%的資料用於測試資料集,random_state=5。
請用Data來預測Target的值。
請使用round函數計算至小數點第二位,印出所訓練分類器的準確度【xx.xx】%,並預測分類。
(三)、 請依序回答下列問題:
1.請填入分類器的準確度Accuracy of the classifier為多少%(不需填入%,計算至小數點後第二位)?
2.輸入資料[1.51, 1.73, 1.98, 20.15, 85, 2.2, 1.92, .32, 1.48, 2.94, 1, 3.57, 172],請填入預測分類的選項?
( A ) 第1類 ( B ) 第2類 ( C ) 第3類 ( D ) 無法分類
3.輸入資料[14.23, 1.71, 2.43, 15.6, 127, 2.8, 3.06, .28, 2.29, 5.64, 1.04, 3.92, 1065],請填入預測分類的選項?
( A ) 第1類 ( B ) 第2類 ( C ) 第3類 ( D ) 無法分類
4.輸入資料[13.71, 5.65, 2.45, 20.5, 95, 1.68, .61, .52, 1.06, 7.7, .64, 1.74, 720],請填入預測分類的選項?
( A ) 第1類 ( B ) 第2類 ( C ) 第3類 ( D ) 無法分類參考解答:
import numpy as np
import pandas as pd
input_file = 'wine.csv'
data = pd.read_csv(input_file, header=None, names=['Target'] + [f'Data_{i}' for i in range(1, 14)])
X = data.iloc[:, 1:].values
y = data.iloc[:, 0].values
from sklearn import model_selection
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.25, random_state=5)
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier(random_state=5)
classifier.fit(X_train, y_train)
accuracy = round(classifier.score(X_test, y_test) * 100, 2)
print("Accuracy of the classifier =", accuracy, "%")
X_test1 = [[1.51, 1.73, 1.98, 20.15, 85, 2.2, 1.92, .32, 1.48, 2.94, 1, 3.57, 172]]
X_test2 = [[14.23, 1.71, 2.43, 15.6, 127, 2.8, 3.06, .28, 2.29, 5.64, 1.04, 3.92, 1065]]
X_test3 = [[13.71, 5.65, 2.45, 20.5, 95, 1.68, .61, .52, 1.06, 7.7, .64, 1.74, 720]]
prediction1 = classifier.predict(X_test1)[0]
prediction2 = classifier.predict(X_test2)[0]
prediction3 = classifier.predict(X_test3)[0]
print(f"預測分類 (X_test1): {prediction1} 類")
print(f"預測分類 (X_test2): {prediction2} 類")
print(f"預測分類 (X_test3): {prediction3} 類")程式解析:
import numpy as np # 導入 NumPy 函式庫,用於數值運算,特別是處理陣列。
import pandas as pd # 導入 Pandas 函式庫,用於資料處理,尤其是讀取 CSV 檔案。
input_file = 'wine.csv' # 定義輸入檔案的路徑和名稱。
# 讀取 CSV 檔案。header=None 表示檔案沒有表頭,names 參數定義了每一列的名稱。
# 欄位0是Target,其餘13個是Data。
data = pd.read_csv(input_file, header=None, names=['Target'] + [f'Data_{i}' for i in range(1, 14)])
X = data.iloc[:, 1:].values # 從 DataFrame 中選取所有列和第1欄到最後一欄(即Data部分),並將其轉換為 NumPy 陣列,作為特徵資料 X。
y = data.iloc[:, 0].values # 從 DataFrame 中選取所有列和第0欄(即Target部分),並將其轉換為 NumPy 陣列,作為目標變數 y。
from sklearn import model_selection # 從 scikit-learn 導入 model_selection 模組,用於資料分割。
# 將資料集分割為訓練集和測試集。
# test_size=0.25 表示 25% 的資料用於測試,75% 用於訓練。
# random_state=5 確保每次執行分割的結果都相同,便於重現。
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.25, random_state=5)
from sklearn.tree import DecisionTreeClassifier # 從 scikit-learn 導入 DecisionTreeClassifier,這是決策樹分類器。
# 初始化決策樹分類器模型。
classifier = DecisionTreeClassifier(random_state=5) # 設置 random_state 確保每次訓練結果一致。
classifier.fit(X_train, y_train) # 使用訓練資料 (X_train, y_train) 來訓練決策樹模型。
# 計算分類器的準確度。
# classifier.score(X_test, y_test) 會返回模型在測試集上的準確度(0到1之間)。
# 乘以 100 轉換為百分比,round(..., 2) 四捨五入到小數點後兩位。
accuracy = round(classifier.score(X_test, y_test) * 100, 2)
print("Accuracy of the classifier =", accuracy, "%") # 印出分類器的準確度。
# 定義要預測的新資料。
X_test1 = [[1.51, 1.73, 1.98, 20.15, 85, 2.2, 1.92, .32, 1.48, 2.94, 1, 3.57, 172]]
X_test2 = [[14.23, 1.71, 2.43, 15.6, 127, 2.8, 3.06, .28, 2.29, 5.64, 1.04, 3.92, 1065]]
X_test3 = [[13.71, 5.65, 2.45, 20.5, 95, 1.68, .61, .52, 1.06, 7.7, .64, 1.74, 720]]
# 使用訓練好的分類器對新的輸入資料進行預測。
# predict() 方法會返回預測的類別標籤。
prediction1 = classifier.predict(X_test1)[0] # 預測 X_test1 的類別,[0] 取出陣列中的第一個元素。
prediction2 = classifier.predict(X_test2)[0] # 預測 X_test2 的類別。
prediction3 = classifier.predict(X_test3)[0] # 預測 X_test3 的類別。
# 印出預測結果,以便回答問題2、3、4。
print(f"預測分類 (X_test1): {prediction1} 類")
print(f"預測分類 (X_test2): {prediction2} 類")
print(f"預測分類 (X_test3): {prediction3} 類")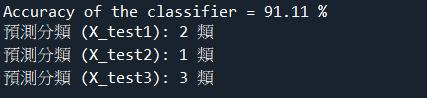

Yiru@Studio - 關於我 - 意如