文、意如

題目:
1.著名的鐵達尼號乘客資料是一份公開資訊,我們使用邏輯迴歸進行鐵達尼號的生存預測。
2.請撰寫程式,讀取titanic.csv;其中年齡(Age)欄位的NA值,請以年齡的中位數代入。
3.使用乘客等級(PClass)、年齡(Age)和性別碼(SexCode)三個欄位的資料來訓練邏輯迴歸預測模型。
(三)、 請依序回答下列問題:
1.請填入年齡的中位數(取至整數)?
2.請填入此模型的截距(intercept_)(四捨五入取至小數點後第四位)?
3.請填入此模型中,性別碼(SexCode)的迴歸係數(四捨五入取至小數點後第四位)?
4.請填入此預測模型的準確度(四捨五入取至小數點後第四位)MLD02.py
import pandas as pd
import numpy as np
from sklearn import preprocessing, linear_model
# 原始資料
titanic = pd.read_csv("titanic.csv")
print('raw data')
# TODO
# 將年齡的空值填入年齡的中位數
# TODO
print("年齡中位數=" )
# TODO
# 更新後資料
print('new data')
# TODO
# 轉換欄位值成為數值
label_encoder = preprocessing.LabelEncoder()
encoded_class = label_encoder.fit_transform( )
# TODO
# 建立模型
# TODO
print('截距=' )
print('迴歸係數=' )
# 混淆矩陣(Confusion Matrix),計算準確度
print('Confusion Matrix')
# TODO
參考解答:
import pandas as pd
import numpy as np
from sklearn import preprocessing, linear_model
titanic = pd.read_csv("titanic.csv")
df = titanic.copy()
df.info()
age_median = df.Age.median()
df.Age.fillna(age_median, inplace=True)
df.info()
print(f"年齡中位數= {age_median:.0f}")
le = preprocessing.LabelEncoder()
df.PClass = le.fit_transform(df.PClass)
X = df.loc[:, ['PClass', 'Age', 'SexCode']]
y = df.loc[:, 'Survived']
model = linear_model.LogisticRegression()
model.fit(X, y)
intercept = model.intercept_
coef = model.coef_
print(f'截距= {intercept[0]:.4f}')
print(f'迴歸係數= {coef[0][2]:.4f}')
accuracy = model.score(X, y)
print(f'accuracy: {accuracy:.4f}')程式解析:
import pandas as pd # 導入 pandas 函式庫,主要用於資料處理和分析,尤其是讀取 CSV 檔案和操作 DataFrame。
import numpy as np # 導入 numpy 函式庫,用於數值運算,例如計算中位數。
from sklearn import preprocessing, linear_model # 從 scikit-learn 導入 preprocessing (資料預處理模組,包含 LabelEncoder) 和 linear_model (線性模型模組,包含 LogisticRegression)。
# 原始資料
titanic = pd.read_csv("titanic.csv") # 讀取名為 "titanic.csv" 的 CSV 檔案,將其內容載入到一個 pandas DataFrame 中,變數名為 titanic。
df = titanic.copy() # 建立 titanic DataFrame 的一個副本 (copy),將其賦值給 df。這樣做是為了避免直接修改原始 titanic DataFrame,確保後續操作不會影響到原始數據。
# 將年齡的空值填入年齡的中位數
df.info() # 印出 df DataFrame 的摘要資訊,包括每列的資料型態、非空值數量以及記憶體使用情況。這有助於檢查缺失值。
age_median = df.Age.median() # 計算 df DataFrame 中 'Age' 欄位的中位數,並將結果儲存到 age_median 變數中。
df.Age.fillna(age_median, inplace=True) # 使用 fillna() 方法,將 df DataFrame 中 'Age' 欄位的所有缺失值 (NaN) 替換為計算出的 age_median。inplace=True 表示直接在 df 上進行修改,而不是返回一個新的 DataFrame。
df.info() # 再次印出 df DataFrame 的摘要資訊,用於確認 'Age' 欄位中的缺失值是否已被成功填充。
print(f"年齡中位數= {age_median:.0f}") # 印出年齡的中位數,使用 f-string 格式化為整數 (小數點後 0 位)。
# 轉換欄位值成為數值
le = preprocessing.LabelEncoder() # 初始化一個 LabelEncoder 物件。LabelEncoder 用於將非數值的類別標籤 (例如 '1st', '2nd') 轉換為數值標籤 (例如 0, 1, 2)。
df.PClass = le.fit_transform(df.PClass) # 使用 LabelEncoder 對 df DataFrame 中的 'PClass' 欄位進行擬合 (fit) 和轉換 (transform)。這會將 'PClass' 中的類別字串轉換為對應的數值,並將結果直接儲存回 'PClass' 欄位。
X = df.loc[:, ['PClass', 'Age', 'SexCode']] # 從 df DataFrame 中選取所有列 (:),以及 'PClass', 'Age', 'SexCode' 這三個欄位,將它們作為特徵數據 (自變數) 賦值給 X。
y = df.loc[:, 'Survived'] # 從 df DataFrame 中選取所有列 (:),以及 'Survived' 欄位,將它作為目標變數 (因變數) 賦值給 y。
# 建立模型
model = linear_model.LogisticRegression() # 初始化一個 LogisticRegression (邏輯迴歸) 模型物件。這是用於二元分類問題的線性模型。
model.fit(X, y) # 使用特徵數據 X 和目標變數 y 來訓練 (fit) 邏輯迴歸模型。模型會在此步驟中學習數據中的模式。
intercept = model.intercept_ # 從訓練好的模型中獲取截距 (intercept_)。截距是當所有特徵都為零時,預測值的對數幾率。
coef = model.coef_ # 從訓練好的模型中獲取迴歸係數 (coef_)。這些係數表示每個特徵對預測結果的影響程度。
print(f'截距= {intercept[0]:.4f}') # 印出模型的截距,使用 f-string 格式化為小數點後四位。由於 intercept_ 是一個陣列,我們取第一個元素。
# 注意:這裡 `coef[0][2]` 表示取第一個類別(如果有)的第一組係數中的第三個係數。
# 根據 `X` 的欄位順序 `['PClass', 'Age', 'SexCode']`,第三個係數 (`[2]`) 對應的是 'SexCode'。
print(f'迴歸係數= {coef[0][2]:.4f}') # 印出模型中 'SexCode' 欄位的迴歸係數,使用 f-string 格式化為小數點後四位。
# 混淆矩陣(Confusion Matrix),計算準確度
accuracy = model.score(X, y) # 使用訓練好的模型,計算其在訓練數據 (X, y) 上的準確度。model.score() 方法返回的是平均準確度。
print(f'accuracy: {accuracy:.4f}') # 印出模型的準確度,使用 f-string 格式化為小數點後四位。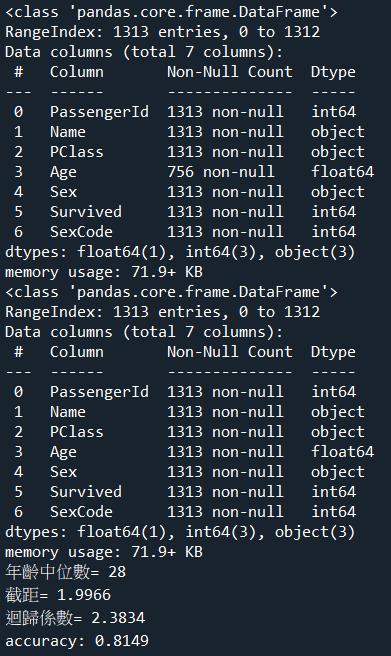


Yiru@Studio - 關於我 - 意如