文、意如

題目:
1.請使用隨機森林分類(Random Forest Classifier),撰寫程式,讀取汽車評估資料集cardata.txt,
資料集中的前六個屬性為input_data,用來進行對第七個屬性(汽車可接受度)的分類。其取值範圍如下,每一列都包含由逗號分隔的單字清單,請將之解析分割。
欄位名稱 說明
buying 買價 取值範圍是vhigh、 high、 med、 low
maint 維修保養價格 取值範圍是vhigh、 high、 med、 low
doors 門數 取值範圍是2、 3、 4、 5等,5門含5門以上資料表示成5more
persons 載人量 取值範圍是2、 4等,超過4人資料表示成more
lug_boot 行李箱的大小 取值範圍是small、 med、 big
safety 安全 取值範圍是low、 med、 high
car 汽車可接受度 unacc為不可接受,acc為可接受, good為良好,vgood為非常好
2.請用三折交叉驗證(three-fold cross-validation,將數據分三組,輪換著用其中兩組資料驗證分類器)來計算分類器的準確性。
參數設定n_estimators=200, max_depth=8, random_state=7。
3.input_data = ['high', 'low', '2', 'more', 'med', 'high'](前面六個屬性),依據輸入值預測輸入類別Output class。
4請用與前相同之分類器進行"n_estimators"超參數最佳化,
參數設定max_depth=8, random_state=7, parameter_grid=np.linspace(25, 200, 8).astype(int),且改用cv=5。
(三)、 請依序回答下列問題:
1.請填入分類器的準確度Accuracy of the classifier為多少%(不需填入%,四捨五入計算至小數點後第二位)?
2.input_data = ['high', 'low', '2', 'more', 'med', 'high'](前面六個屬性)。請依據輸入值,填入預測類別的選項?
( A ) unacc ( B ) acc ( C ) good ( D ) vgood
3.請填入"n_estimators"此一超參數的Training scores第一組第一筆數值(計算至小數點第四位後無條件捨去)?
4.請填入"n_estimators"此一超參數的Validation scores最後一組第一筆數值(計算至小數點第四位後無條件捨去)?MLD01.py
import numpy as np
from sklearn import preprocessing
from sklearn.ensemble import RandomForestClassifier
#import matplotlib.pyplot as plt
input_file = 'cardata.txt'
# Reading the data
X = []
y = []
# TODO
# Convert string data to numerical data將字串資料轉換為數值資料
# TODO
# Build a Random Forest classifier建立隨機森林分類器
# TODO
# Cross validation交叉驗證
from sklearn import model_selection
# TODO
print("Accuracy of the classifier=" + + "%")
# Testing encoding on single data instance測試單個資料實例上的編碼
input_data = ['high', 'low', '2', 'more', 'med', 'high']
# TODO
# Predict and print output for a particular datapoint
# TODO
print("Output class=" )
########################
# Validation curves 驗證曲線
# TODO
train_scores, validation_scores = validation_curve(classifier, X, y,
"n_estimators", parameter_grid, cv=5)
print("##### VALIDATION CURVES #####")
print("\nParam: n_estimators\nTraining scores:\n", train_scores)
print("\nParam: n_estimators\nValidation scores:\n", validation_scores)
參考解答:
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
data = pd.read_csv('cardata.txt', header=None)
df = data.copy()
from sklearn.preprocessing import LabelEncoder
le_en = []
for i in range(df.shape[1]):
le = LabelEncoder().fit(df[i])
le_en.append(le)
df[i] = le_en[-1].transform(df[i])
X = df.iloc[:, :-1]
y = df.iloc[:, -1]
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=200, max_depth=8, random_state=7)
model.fit(X, y)
from sklearn.model_selection import cross_validate
cv_dic = cross_validate(model, X, y, cv=3)
score = (cv_dic.get('test_score')).mean()
print(f"Accuracy of the classifier= {score*100:.2f} %")
input_data = pd.DataFrame(['high', 'low', '2', 'more', 'med', 'high']).T
for i in range(input_data.shape[1]):
input_data[i] = le_en[i].transform(input_data[i])
input_pred = model.predict(input_data)
label = le_en[-1].inverse_transform(input_pred)
print(f"Output class= {label[0]}")
parameter_grid = np.linspace(25, 200, 8).astype(int)
from sklearn.model_selection import validation_curve
train_scores, validation_scores = validation_curve(model, X, y,
'n_estimators', parameter_grid, cv=5)
print("##### VALIDATION CURVES #####")
print("\nParam: n_estimators\nTraining scores:\n", train_scores)
print("\nParam: n_estimators\nValidation scores:\n", validation_scores)程式解析:
import numpy as np # 導入 NumPy 函式庫,主要用於數值運算和處理陣列。
import pandas as pd # 導入 Pandas 函式庫,用於資料處理和分析,特別是讀取 CSV/TXT 檔案和操作 DataFrame。
import warnings # 導入 warnings 模組,用於控制 Python 中的警告訊息。
warnings.filterwarnings("ignore") # 設定警告過濾器,忽略所有警告訊息,讓程式碼執行時不會印出警告。這在最終呈現結果時可能有用,但在開發階段不建議,因為可能錯過重要的問題提示。
data = pd.read_csv('cardata.txt', header=None) # 讀取名為 'cardata.txt' 的文本檔案,將其內容載入到 Pandas DataFrame 中。header=None 表示檔案沒有標頭行,所有行都被視為資料。
df = data.copy() # 建立 data DataFrame 的一個副本 (copy),將其賦值給 df。這樣做是為了避免直接修改原始 data DataFrame,確保後續操作不會影響到原始數據。
from sklearn.preprocessing import LabelEncoder # 從 scikit-learn 導入 LabelEncoder,用於將非數值(類別)資料轉換為數值。
le_en = [] # 初始化一個空列表 le_en,用於儲存每個欄位訓練好的 LabelEncoder 物件。
for i in range(df.shape[1]): # 迴圈遍歷 df DataFrame 的所有欄位 (從第 0 欄到最後一欄)。df.shape[1] 返回 DataFrame 的欄位數量。
le = LabelEncoder().fit(df[i]) # 為當前欄位 df[i] 初始化一個 LabelEncoder 物件,並使用該欄位的數據來擬合 (fit) 它,學習如何將類別標籤轉換為數值。
le_en.append(le) # 將訓練好的 LabelEncoder 物件添加到 le_en 列表中。
df[i] = le_en[-1].transform(df[i]) # 使用剛添加到列表中的 LabelEncoder (le_en[-1]) 對當前欄位 df[i] 的數據進行轉換 (transform),將其類別值替換為數值。
X = df.iloc[:, :-1] # 從 df DataFrame 中選取所有行 (:),以及除了最後一欄之外的所有欄位 (:-1),將它們作為特徵數據 (自變數) 賦值給 X。
y = df.iloc[:, -1] # 從 df DataFrame 中選取所有行 (:),以及最後一欄 (-1),將它作為目標變數 (因變數) 賦值給 y。
from sklearn.ensemble import RandomForestClassifier # 從 scikit-learn 導入 RandomForestClassifier,這是一個基於決策樹的集成學習模型 (隨機森林分類器)。
model = RandomForestClassifier(n_estimators=200, max_depth=8, random_state=7) # 初始化一個 RandomForestClassifier 模型物件。
# n_estimators=200: 森林中決策樹的數量為 200 棵。
# max_depth=8: 每棵決策樹的最大深度為 8。
# random_state=7: 設置隨機種子,確保每次執行模型訓練的結果都相同,便於重現。
model.fit(X, y) # 使用特徵數據 X 和目標變數 y 來訓練 (fit) 隨機森林模型。
from sklearn.model_selection import cross_validate # 從 scikit-learn 導入 cross_validate,用於執行交叉驗證。
cv_dic = cross_validate(model, X, y, cv=3) # 對訓練好的 model 執行交叉驗證。
# model: 要評估的模型。
# X, y: 特徵數據和目標變數。
# cv=3: 指定 K 折交叉驗證的折數為 3。這表示數據會被分成 3 份,模型會訓練 3 次,每次使用不同的 2 份作為訓練集,1 份作為測試集。
# cv_dic 會返回一個字典,包含訓練分數、測試分數、訓練時間、測試時間等。
score = (cv_dic.get('test_score')).mean() # 從 cv_dic 字典中獲取 'test_score' (即每次交叉驗證在測試集上的準確度分數),然後計算這些分數的平均值。
print(f"Accuracy of the classifier= {score*100:.2f} %") # 印出分類器的平均準確度,將其轉換為百分比並格式化為小數點後兩位。
input_data = pd.DataFrame(['high', 'low', '2', 'more', 'med', 'high']).T # 創建一個新的 Pandas DataFrame,包含要預測的單一數據點。.T 用於轉置,使其成為一行多列的形式,以符合模型輸入的格式。
for i in range(input_data.shape[1]): # 迴圈遍歷 input_data DataFrame 的所有欄位。
# 使用之前儲存在 le_en 列表中的對應 LabelEncoder 物件,對 input_data 的每個欄位進行轉換。
# le_en[i] 確保對應的轉換器用於對應的欄位。
input_data[i] = le_en[i].transform(input_data[i]) # 將 input_data 中第 i 欄的類別值轉換為數值。
input_pred = model.predict(input_data) # 使用訓練好的模型 (model) 對轉換後的 input_data 進行預測,得到預測結果。
label = le_en[-1].inverse_transform(input_pred) # 使用 le_en 列表中最後一個 LabelEncoder 物件 (le_en[-1]) 對預測結果 (input_pred,它是數值) 進行反向轉換 (inverse_transform),將數值標籤轉換回原始的類別標籤(即輸出類別)。
print(f"Output class= {label[0]}") # 印出預測的輸出類別。由於 label 是一個陣列,我們取第一個元素。
parameter_grid = np.linspace(25, 200, 8).astype(int) # 生成一個數值範圍在 25 到 200 之間,包含 8 個等間隔整數的陣列。這將用作 n_estimators 參數的測試值。
from sklearn.model_selection import validation_curve # 從 scikit-learn 導入 validation_curve,用於評估模型在不同超參數值下的性能。
train_scores, validation_scores = validation_curve(model, X, y, # 執行驗證曲線計算。
'n_estimators', parameter_grid, cv=5) #
# model: 要評估的模型。
# X, y: 訓練數據和目標變數。
# 'n_estimators': 要調整的超參數名稱。
# parameter_grid: n_estimators 超參數的測試值列表。
# cv=5: 指定 K 折交叉驗證的折數為 5。
# train_scores 會返回模型在不同 n_estimators 值下,訓練集上的分數。
# validation_scores 會返回模型在不同 n_estimators 值下,驗證集 (測試折) 上的分數。
print("##### VALIDATION CURVES #####") # 印出標題,表示接下來是驗證曲線的結果。
print("\nParam: n_estimators\nTraining scores:\n", train_scores) # 印出 n_estimators 參數下,模型在訓練集上的分數。
print("\nParam: n_estimators\nValidation scores:\n", validation_scores) # 印出 n_estimators 參數下,模型在驗證集 (測試折) 上的分數。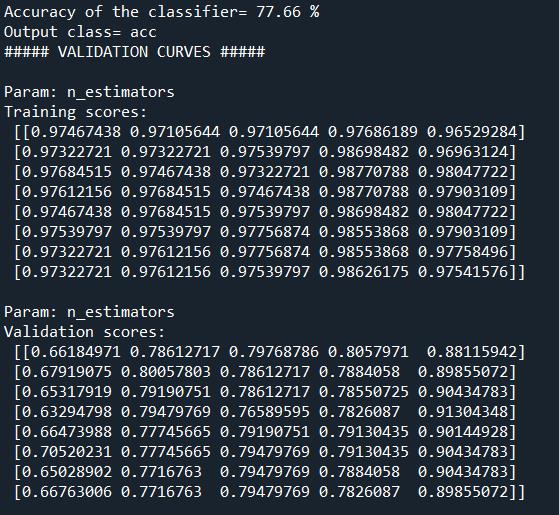

Yiru@Studio - 關於我 - 意如