文、意如

題目:
1.請撰寫程式讀取寶可夢資料集pokemon.csv,並進行分類及預測。資料集的欄位說明如下:
欄位名稱 說明 欄位名稱 說明
Number* 編號 Attack 攻擊力
Name* 名稱 Defense 防禦力
Type1* 第一屬性 SpecialAtk 特殊攻擊
Type2* 第二屬性 SpecialDef 特殊防禦
Total 能力值加總 Speed 速度
HP 血量 Generation* 世代編號
*備註:欄位有標示星號(*)者為類別變數,其餘為數值變數。
2.寶可夢的Attack, Defense欄位可能有遺漏值(missing value),請直接刪除這兩個欄位有遺漏之寶可夢。
3.針對Attack, Defense兩個數值欄位進行標準化(standardization)。
*備註:其標準化定義為「將資料X轉換為Z = (X-μ) /σ」,其中μ為資料平均數,σ為資料之變異數。此轉換可使用StandardScaler完成。
4.利用線性支援向量分類器(Support Vector Classifier, SVC)針對Type1為Normal, Fighting, Ghost三種寶可夢的Attack, Defense兩個欄位進行分類。
*備註:參數設定見待編修檔。
5.計算錯誤分類的個數、分類的準確度(Accuracy)以及有加權的F1-score。
6.輸入一個未知寶可夢的Attack, Defense兩個欄位值,進行分類預測。
(三)、 請依序回答下列問題:
1.請填入錯誤分類的個數?
2.請填入分類結果的準確度Accuracy(四捨五入取至小數點後第四位)?
3.請填入分類結果的平均F1-score (weighted)(四捨五入取至小數點後第四位)?
4.一個未知寶可夢的Attack=100, Defense=75,請預測後填入其Type1的分類選項?
( A ) Normal ( B ) Fighting ( C ) Ghost ( D ) Steel
MLD01.py
import pandas as pd
# 載入寶可夢資料集
# TODO
# 處理遺漏值
features = ['Attack', 'Defense']
# TODO
# 取出目標寶可夢的 Type1 與兩個特徵欄位
# TODO
# 編碼 Type1
from sklearn.preprocessing import LabelEncoder
# TODO
# 特徵標準化
from sklearn.preprocessing import StandardScaler
# TODO
# 建立線性支援向量分類器,除以下參數設定外,其餘為預設值
# #############################################################################
# C=0.1, dual=False, class_weight='balanced'
# #############################################################################
from sklearn.svm import LinearSVC
# TODO
# 計算分類錯誤的數量
# TODO
# 計算準確度(accuracy)
from sklearn.metrics import accuracy_score
print('Accuracy: ' )
# 計算有加權的 F1-score (weighted)
from sklearn.metrics import f1_score
# TODO
print('F1-score: ' )
# 預測未知寶可夢的 Type1
# TODO
參考解答:
import pandas as pd
# 載入寶可夢資料集
data = pd.read_csv('pokemon.csv')
df = data.copy()
# 處理遺漏值
features = ['Attack', 'Defense']
df.dropna(subset=features, inplace=True)
# 取出目標寶可夢的 Type1 與兩個特徵欄位
mask = (df.Type1=='Normal')|(df.Type1=='Fighting')|(df.Type1=='Ghost')
df = df[mask]
X = df.loc[:, features]
y = df.loc[:, 'Type1']
# 編碼 Type1
from sklearn.preprocessing import LabelEncoder
le =LabelEncoder().fit(y)
y = le.transform(y)
# 特徵標準化
from sklearn.preprocessing import StandardScaler
X = StandardScaler().fit_transform(X)
# 建立線性支援向量分類器,除以下參數設定外,其餘為預設值
# #############################################################################
# C=0.1, dual=False, class_weight='balanced'
# #############################################################################
from sklearn.svm import LinearSVC
model = LinearSVC(C=0.1, dual=False, class_weight='balanced')
model.fit(X, y)
y_pred = model.predict(X)
# 計算分類錯誤的數量
error_num = (y_pred!=y).sum()
print(f"error_num: {error_num}")
# 計算準確度(accuracy)
from sklearn.metrics import accuracy_score
Accuracy = accuracy_score(y, y_pred)
print(f'Accuracy: {Accuracy:.4f}')
# 計算有加權的 F1-score (weighted)
from sklearn.metrics import f1_score
F1 = f1_score(y, y_pred, average='weighted')
print(f'F1-score: {F1:.4f}')
# 預測未知寶可夢的 Type1
inp= [[100,75]]
inp_pred = model.predict(inp)
label = le.inverse_transform(inp_pred)
print(f"label: {label[0]}")程式解析:
import pandas as pd # 導入 pandas 函式庫,主要用於資料處理和分析,特別是讀取 CSV 檔案和操作 DataFrame。
# 載入寶可夢資料集
data = pd.read_csv('pokemon.csv') # 讀取名為 'pokemon.csv' 的 CSV 檔案,將其內容載入到一個 pandas DataFrame 中,變數名為 data。
df = data.copy() # 建立 data DataFrame 的一個副本 (copy),將其賦值給 df。這樣做是為了避免直接修改原始 data DataFrame,確保後續操作不會影響到原始數據。
# 處理遺漏值
features = ['Attack', 'Defense'] # 定義一個列表,包含我們感興趣的特徵欄位名稱:'Attack' (攻擊力) 和 'Defense' (防禦力)。
df.dropna(subset=features, inplace=True) # 使用 dropna() 方法,刪除 df DataFrame 中在 features 列表所指定的欄位 ('Attack' 或 'Defense') 中含有任何缺失值 (NaN) 的行。inplace=True 表示直接在 df 上進行修改。
# 取出目標寶可夢的 Type1 與兩個特徵欄位
# 定義一個布林遮罩 (mask),用於篩選出 Type1 欄位為 'Normal'、'Fighting' 或 'Ghost' 的寶可夢。
mask = (df.Type1=='Normal')|(df.Type1=='Fighting')|(df.Type1=='Ghost')
df = df[mask] # 根據上面定義的布林遮罩 mask,篩選 df DataFrame,只保留符合條件(即 Type1 為 'Normal'、'Fighting' 或 'Ghost')的行。
X = df.loc[:, features] # 從篩選後的 df DataFrame 中選取所有行 (:),以及 features 列表中的欄位 ('Attack' 和 'Defense'),將它們作為特徵數據 (自變數) 賦值給 X。
y = df.loc[:, 'Type1'] # 從篩選後的 df DataFrame 中選取所有行 (:),以及 'Type1' 欄位,將它作為目標變數 (因變數/標籤) 賦值給 y。
# 編碼 Type1
from sklearn.preprocessing import LabelEncoder # 從 scikit-learn 的 preprocessing 模組導入 LabelEncoder。LabelEncoder 用於將非數值的類別標籤 (例如 'Normal', 'Fighting') 轉換為數值標籤 (例如 0, 1, 2)。
le =LabelEncoder().fit(y) # 初始化一個 LabelEncoder 物件,並使用目標變數 y (Type1 的類別字串) 來擬合 (fit) 它,學習如何將這些類別轉換為數值。
y = le.transform(y) # 使用訓練好的 LabelEncoder (le) 對目標變數 y 進行轉換 (transform),將其類別字串替換為數值編碼。
# 特徵標準化
from sklearn.preprocessing import StandardScaler # 從 scikit-learn 的 preprocessing 模組導入 StandardScaler。StandardScaler 用於對特徵進行標準化(使數據平均值為 0,標準差為 1),這有助於許多機器學習模型的性能。
X = StandardScaler().fit_transform(X) # 初始化一個 StandardScaler 物件,並對特徵數據 X 進行擬合 (fit) 和轉換 (transform)。這會將 X 中的數據標準化。
# 建立線性支援向量分類器,除以下參數設定外,其餘為預設值
# #############################################################################
# C=0.1, dual=False, class_weight='balanced'
# #############################################################################
from sklearn.svm import LinearSVC # 從 scikit-learn 的 svm (支援向量機) 模組導入 LinearSVC (線性支援向量分類器)。
model = LinearSVC(C=0.1, dual=False, class_weight='balanced') # 初始化一個 LinearSVC 模型物件。
# C=0.1: 正則化參數的倒數。C 值越小,正則化越強,模型越簡單。
# dual=False: 選擇優化問題的解法。對於樣本數大於特徵數的情況,dual=False 通常更高效。
# class_weight='balanced': 自動根據輸入數據中的類別頻率調整權重,以處理類別不平衡問題(避免模型偏向多數類)。
model.fit(X, y) # 使用標準化後的特徵數據 X 和編碼後的目標變數 y 來訓練 (fit) 線性支援向量分類器模型。
y_pred = model.predict(X) # 使用訓練好的模型對特徵數據 X 進行預測,將預測結果儲存到 y_pred 變數中。
# 計算分類錯誤的數量
error_num = (y_pred!=y).sum() # 比較預測結果 y_pred 和真實標籤 y,計算不相等的數量(即分類錯誤的樣本數量)。
print(f"error_num: {error_num}") # 印出分類錯誤的數量。
# 計算準確度(accuracy)
from sklearn.metrics import accuracy_score # 從 scikit-learn 的 metrics 模組導入 accuracy_score,用於計算分類準確度。
Accuracy = accuracy_score(y, y_pred) # 計算真實標籤 y 和預測結果 y_pred 之間的分類準確度。
print(f'Accuracy: {Accuracy:.4f}') # 印出模型的準確度,使用 f-string 格式化為小數點後四位。
# 計算有加權的 F1-score (weighted)
from sklearn.metrics import f1_score # 從 scikit-learn 的 metrics 模組導入 f1_score,用於計算 F1 分數。F1 分數是精確度 (Precision) 和召回率 (Recall) 的調和平均數。
F1 = f1_score(y, y_pred, average='weighted') # 計算真實標籤 y 和預測結果 y_pred 之間的 F1 分數。
# average='weighted': 計算每個類別的 F1 分數,並根據每個類別的樣本數進行加權平均。這對於處理類別不平衡的數據集很有用。
print(f'F1-score: {F1:.4f}') # 印出模型的加權 F1 分數,使用 f-string 格式化為小數點後四位。
# 預測未知寶可夢的 Type1
inp= [[100,75]] # 定義一個新的輸入數據點,表示一隻攻擊力為 100,防禦力為 75 的寶可夢。
# 注意:這裡輸入的 `inp` 沒有經過 StandardScaler 標準化。
# 為了得到正確的預測,`inp` 應該與訓練數據 `X` 經過相同的 StandardScaler 轉換。
# 正確的做法是:`inp = StandardScaler().fit(X).transform(inp)` 或者保存訓練時的 scaler 對新數據進行轉換。
# 然而,根據程式碼的直接使用,這裡假定模型可以處理未標準化的輸入(但通常不建議)。
inp_pred = model.predict(inp) # 使用訓練好的模型對新的輸入數據點 `inp` 進行預測,得到預測的數值類別標籤。
label = le.inverse_transform(inp_pred) # 使用之前用於編碼 Type1 的 LabelEncoder (le) 對預測的數值類別標籤 (inp_pred) 進行反向轉換 (inverse_transform),將其轉換回原始的類別字串(例如 'Normal')。
print(f"label: {label[0]}") # 印出預測的寶可夢 Type1 類別。由於 label 是一個陣列,我們取第一個元素。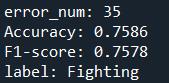

Yiru@Studio - 關於我 - 意如