文、意如

題目:
1.請使用線性迴歸預測方式撰寫程式,讀取NBApoints.csv,此資料收集了NBA球員的資訊。
2.NBApoints.csv其中每一行都包含用逗號分隔的字串格式等共30個欄位,資料集的欄位簡易說明如下,其餘省略。
欄位名稱 說明
Rk 排名
Player 球員
Pos 守備位置
Age 年齡
Tm 隊名
3. 請將Pos欄位及Tm欄位資料轉換為數值,以利進行後續處理。 4. 接著建立機器學習模型並預測。以Pos、Age、Tm三個欄位進行訓練。 5. 運用sklearn.metrics交叉驗證,計算出Mean squared error(MSE)、R-squared與P-value。
(三)、 請依序回答下列問題:
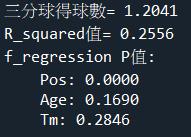
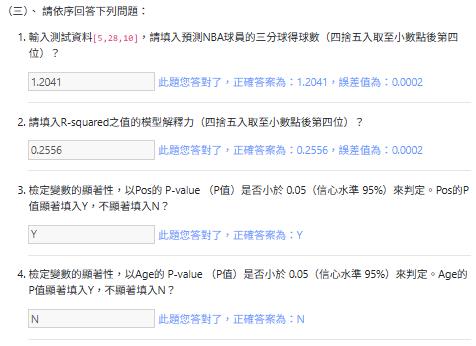
1.輸入測試資料[5,28,10],請填入預測NBA球員的三分球得球數(四捨五入取至小數點後第四位)?
2.請填入R-squared之值的模型解釋力(四捨五入取至小數點後第四位)?
3.檢定變數的顯著性,以Pos的 P-value (P值)是否小於 0.05(信心水準 95%)來判定。Pos的P值顯著填入Y,不顯著填入N?
4.檢定變數的顯著性,以Age的 P-value (P值)是否小於 0.05(信心水準 95%)來判定。Age的P值顯著填入Y,不顯著填入N?
MLD01.py
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.feature_selection import f_regression
NBApoints_data= pd.read_csv("NBApoints.csv")
#TODO
label_encoder_conver = preprocessing.LabelEncoder()
Pos_encoder_value =
print(Pos_encoder_value)
print("\n")
label_encoder_conver = preprocessing.LabelEncoder()
Tm_encoder_value =
print(Tm_encoder_value)
train_X = pd.DataFrame( , ).T
NBApoints_linear_model = LinearRegression()
NBApoints_linear_model.fit(train_X, NBApoints_data["3P"])
NBApoints_linear_model_predict_result=
print("三分球得球數=",NBApoints_linear_model_predict_result)
r_squared =
print("R_squared值=",r_squared)
print("f_regresstion\n")
print("P值=" )
print("\n")
參考解答
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.feature_selection import f_regression
from sklearn import preprocessing
NBApoints_data= pd.read_csv("NBApoints.csv")
df = NBApoints_data.copy()
le_pos = preprocessing.LabelEncoder().fit(df.Pos)
df.Pos =le_pos.transform(df.Pos)
le_tm = preprocessing.LabelEncoder().fit(df.Tm)
df.Tm = le_tm.transform(df.Tm)
features = ['Pos', 'Age', 'Tm']
X = df.loc[:, features]
y = df.loc[:, '3P']
model = LinearRegression()
model.fit(X, y)
y_pred = model.predict(X)
inp = pd.DataFrame([5, 28, 10]).T
inp_pred = model.predict(inp)
print(f"三分球得球數= {inp_pred[0]:.4f}")
r_squared = model.score(X, y)
print(f"R_squared值= {r_squared:.4f}")
pvalue = f_regression(X, y)[1]
print("f_regression P值:")
for i, feature_name in enumerate(features):
print(f"\t{feature_name}: {pvalue[i]:.4f}") 程式解析:
import pandas as pd # 導入 pandas 函式庫,主要用於資料處理和分析,特別是讀取 CSV 檔案和操作 DataFrame。
import numpy as np # 導入 numpy 函式庫,通常用於數值計算,雖然在此代碼中沒有直接使用其特定函數,但它是許多科學計算函式庫(如 scikit-learn)的底層依賴。
from sklearn.linear_model import LinearRegression # 從 scikit-learn 函式庫導入 LinearRegression,這是用於執行線性迴歸的類別。
from sklearn.feature_selection import f_regression # 從 scikit-learn 函式庫導入 f_regression,用於計算特徵與目標變數之間的 F-value 和 p-value。
from sklearn import preprocessing # 從 scikit-learn 函式庫導入 preprocessing 模組,包含許多資料預處理的工具,例如 LabelEncoder。
NBApoints_data= pd.read_csv("NBApoints.csv") # 讀取名為 "NBApoints.csv" 的 CSV 檔案,將其內容載入到一個 pandas DataFrame 中,變數名為 NBApoints_data。
df = NBApoints_data.copy() # 建立 NBApoints_data DataFrame 的一個副本 (copy),將其賦值給 df。這樣做是為了避免直接修改原始 NBApoints_data DataFrame,確保後續操作不會影響到原始數據。
le_pos = preprocessing.LabelEncoder().fit(df.Pos) # 初始化一個 LabelEncoder 物件,並使用 df DataFrame 中 'Pos' (位置) 欄位的唯一值來擬合 (fit) 它。LabelEncoder 會學習如何將這些類別文字(如 'PG', 'SG' 等)轉換為唯一的數值(如 0, 1, 2)。
df.Pos = le_pos.transform(df.Pos) # 使用訓練好的 LabelEncoder (le_pos) 將 df DataFrame 中 'Pos' 欄位的類別標籤轉換 (transform) 為數值編碼。轉換後的數值直接儲存回 'Pos' 欄位。
le_tm = preprocessing.LabelEncoder().fit(df.Tm) # 初始化另一個 LabelEncoder 物件,並使用 df DataFrame 中 'Tm' (球隊) 欄位的唯一值來擬合 (fit) 它,學習如何將球隊名稱轉換為數值。
df.Tm = le_tm.transform(df.Tm) # 使用訓練好的 LabelEncoder (le_tm) 將 df DataFrame 中 'Tm' 欄位的類別標籤轉換 (transform) 為數值編碼。轉換後的數值直接儲存回 'Tm' 欄位。
features = ['Pos', 'Age', 'Tm'] # 定義一個列表,包含我們要用作預測的特徵欄位名稱:'Pos' (位置), 'Age' (年齡), 'Tm' (球隊)。
X = df.loc[:, features] # 從 df DataFrame 中選取所有列 (:),以及 features 列表中定義的欄位,將它們作為自變數 (特徵) 數據賦值給 X。
y = df.loc[:, '3P'] # 從 df DataFrame 中選取所有列 (:),以及 '3P' (三分球得分) 欄位,將它作為因變數 (目標變數) 賦值給 y。
model = LinearRegression() # 初始化一個 LinearRegression (線性迴歸) 模型物件。線性迴歸用於預測連續型的目標變數。
model.fit(X, y) # 使用特徵數據 X 和目標變數 y 來訓練 (fit) 線性迴歸模型。模型會在此步驟中學習特徵與目標之間的線性關係。
y_pred = model.predict(X) # 使用訓練好的模型對原始特徵數據 X 進行預測,得到預測的三分球得分,結果儲存到 y_pred 變數中。
inp = pd.DataFrame([5, 28, 10]).T # 創建一個新的 pandas DataFrame 作為單一輸入數據點。
# [5, 28, 10] 應該分別代表 'Pos' (已編碼), 'Age', 'Tm' (已編碼) 的值。
# .T 用於轉置 DataFrame,使其成為一行多列的形式,以符合模型 predict 方法通常要求的輸入格式 (樣本數 x 特徵數)。
inp_pred = model.predict(inp) # 使用訓練好的模型對新的單一輸入數據點 `inp` 進行預測,得到預測的三分球得分。
print(f"三分球得球數= {inp_pred[0]:.4f}") # 印出預測的三分球得分數。`inp_pred` 是一個陣列,取其第一個元素,並格式化為小數點後四位。
r_squared = model.score(X, y) # 計算模型在特徵數據 X 和目標變數 y 上的決定係數 (R-squared)。R-squared 值表示模型對目標變數變異性的解釋程度,值越接近 1 越好。
print(f"R_squared值= {r_squared:.4f}") # 印出 R-squared 值,格式化為小數點後四位。
pvalue = f_regression(X, y)[1] # 使用 f_regression 函數計算每個特徵 (X) 與目標變數 (y) 之間的 F-value 和 p-value。
# f_regression 返回兩個陣列:第一個是 F-statistics,第二個是 p-values。
# [1] 表示我們只取回 p-value 的陣列。P值用於判斷每個特徵是否對目標變數有統計顯著的影響。
print("f_regression P值:") # 印出一個標題,表示接下來是每個特徵的 P 值。
for i, feature_name in enumerate(features): # 迴圈遍歷 features 列表中的每個特徵名稱及其索引 (i)。
print(f"\t{feature_name}: {pvalue[i]:.4f}") # 印出每個特徵的名稱以及其對應的 P 值。P 值從 `pvalue` 陣列中根據索引 `i` 取出,並格式化為小數點後四位。
Yiru@Studio - 關於我 - 意如