文、意如

題目:
1.請撰寫一程式,利用sklearn.datasets.samples_generator裡的make_blobs函式產生出資料。
總樣本數200,樣本中心數4,資料集的標準差為0.50,隨機種子為0。
2.請利用K-means 演算法分群(K-means Clustering)來做分群。
3.使用集群內誤差平方和(kmeans.inertia_)來判斷分群數量為何值是比較恰當的,值大於90以上的納入計算。
其中K-means內的參數(分群中心)初始化為「k-means++」,K-means演算法的隨機運作次數為「15」,
隨機產生中心的隨機序列(random state=0),最大迭代次數為200。
(三)、 請依序回答下列問題:
- 請使用集群內誤差平方和(kmeans.inertia_)來判斷分群數量,需取值大於90以上者納入計算,可分為幾群?
- 承上題,只取集群內誤差平方和分數大於90以上的數據,請依據計算後之數據,填入正確的選項(選項內兩組數據需完全相同)?
( A ) [1749.6046, 94.0224] ( B ) [1774.5460, 736.9635] ( C ) [1794.0460, 304.9484] ( D ) [736.9635, 901.0224]
3.請輸入分群後最小中心點X的位置(四捨五入取至小數點後第四位)?
4請輸入分群後最大中心點Y的位置(四捨五入取至小數點後第四位)?
MLD02.py
from matplotlib import pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
from sklearn.cluster import KMeans
# 載入scikit-learn資料集範例資料
# TODO
#inertia_集群內誤差平方和,做轉折判斷法的依據
# TODO
#實作
# TODO
kmeans = # TODO
kmeans_predict=kmeans_fit.predict(X)
print("cluster_centers=" )
參考解答:
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
X,_=make_blobs(n_samples=200,centers=4,cluster_std=0.5,random_state=0)
for i in range(1,10):
kmeans=KMeans(n_clusters=i,init='k-means++',n_init=15,random_state=0,max_iter=200).fit(X)
if kmeans.inertia_ >=90:
print(f'n_clusters:{i}=>{kmeans.inertia_: .4f}')
kmeans=KMeans(n_clusters=4,init='k-means++',n_init=15,random_state=0,max_iter=200).fit(X)
print('cluster_centers',kmeans.cluster_centers_)
程式解析:
from sklearn.datasets import make_blobs # 從 scikit-learn 函式庫導入 make_blobs 函式,用於生成簇狀的樣本數據。
from sklearn.cluster import KMeans # 從 scikit-learn 函式庫導入 KMeans 演算法,用於執行 K-means 分群。
# 生成數據集
# n_samples=200: 總共生成的樣本數為 200 個。
# centers=4: 生成 4 個數據中心(即數據將圍繞 4 個不同的點聚集)。
# cluster_std=0.5: 每個簇內部數據點的標準差為 0.5,控制數據點的緊密程度。
# random_state=0: 設置隨機種子為 0,確保每次運行時生成的數據集都是相同的,便於重現。
X, _ = make_blobs(n_samples=200, centers=4, cluster_std=0.5, random_state=0)
# X: 這是生成的特徵數據(即數據點的座標)。
# _: 這是每個數據點所屬的真實群集標籤,在此程式碼中沒有直接使用,所以用 _ 表示忽略。
# 迭代不同數量的 K (分群中心數) 並計算其集群內誤差平方和 (Inertia_)
for i in range(1, 10): # 迴圈遍歷 K 值從 1 到 9。
# 初始化並訓練 KMeans 模型
# n_clusters=i: 設定當前迴圈的 K 值作為分群的數量。
# init='k-means++': 分群中心初始化策略,使用 K-means++ 演算法,可以智能地選擇初始中心,有助於加速收斂。
# n_init=15: K-means演算法的隨機運作次數為 15。演算法會從不同的隨機初始點運行 15 次,並選擇其中集群內誤差平方和最小(即效果最好)的結果。
# random_state=0: 設置隨機種子,確保每次初始中心選擇和演算法運行的隨機性是可重現的。
# max_iter=200: 設定 K-means 演算法的最大迭代次數為 200。
kmeans = KMeans(n_clusters=i, init='k-means++', n_init=15, random_state=0, max_iter=200).fit(X)
# .fit(X): 使用數據 X 訓練 KMeans 模型。訓練完成後,模型會學習到群集中心和每個數據點的歸屬。
# 檢查集群內誤差平方和是否大於或等於 90
if kmeans.inertia_ >= 90: # 判斷當前 K 值下模型的集群內誤差平方和 (inertia_) 是否大於或等於 90。
# inertia_:表示每個群集中所有數據點到其所屬群集中心距離的平方和的總和。值越小表示群集越緊密。
print(f'n_clusters:{i}=>{kmeans.inertia_:.4f}') # 如果條件滿足,則印出當前 K 值以及其對應的 inertia_ 值,格式化為小數點後四位。
# 使用 K=4 進行最終分群並印出中心點
# 根據之前問題的答案,最佳分群數量為 4,這裡直接設定為 4 來進行最終模型訓練和結果提取。
kmeans = KMeans(n_clusters=4, init='k-means++', n_init=15, random_state=0, max_iter=200).fit(X)
# 再次初始化並訓練一個 KMeans 模型,這次明確設定分群數量為 4。
print('cluster_centers', kmeans.cluster_centers_) # 印出最終訓練好的 KMeans 模型所找到的 4 個群集中心點的座標。
# cluster_centers_:這是一個陣列,每一行代表一個群集中心點的座標。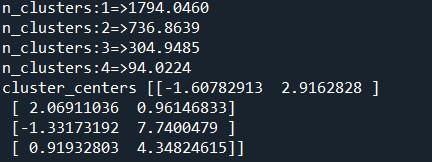
Yiru@Studio - 關於我 - 意如