文、意如

題目:
1.請撰寫程式讀取寶可夢資料集pokemon.json,並進行分群處理。資料集的欄位說明如下:
欄位名稱 說明
HP 血量
Attack 攻擊力
Defense 防禦力
SpecialAtk 特殊攻擊
SpecialDef 特殊防禦
Speed 速度
2. 針對前五個數值欄位進行標準化(Standardization)。 *備註:其標準化定義為「將資料x轉換為Z = (X-μ) /σ」,其中μ為資料平均數,σ為資料之變異數。此轉換可使用StandardScaler完成。
3. 利用階層式集群(Hierarchical clustering)方法把寶可夢分成四群,參數設定: `n_clusters=4, affinity='euclidean', linkage='ward'`。 4. 計算分群結果的最小群與最大群的元素個數。 5. 以分群結果的群內Speed欄位平均值(取至整數)填入兩隻遺漏這個欄位值的寶可夢。
(三)、 請依序回答下列問題:
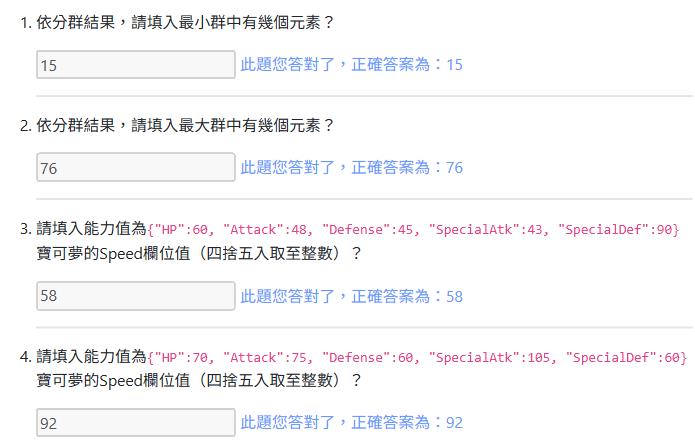
1.依分群結果,請填入最小群中有幾個元素?
2.依分群結果,請填入最大群中有幾個元素?
3.請填入能力值為{"HP":60, "Attack":48, "Defense":45, "SpecialAtk":43, "SpecialDef":90}寶可夢的Speed欄位值(四捨五入取至整數)?
4.請填入能力值為{"HP":70, "Attack":75, "Defense":60, "SpecialAtk":105, "SpecialDef":60}寶可夢的Speed欄位值(四捨五入取至整數)?MLD02.py
import pandas as pd
# 載入寶可夢資料
# TODO
# 取出目標欄位
# TODO
# 特徵標準化
from sklearn.preprocessing import StandardScaler
# TODO
# 利用 Hierarchical Clustering 進行分群,除以下參數設定外,其餘為預設值
# #############################################################################
# n_clusters=4, affinity='euclidean', linkage='ward'
# #############################################################################
from sklearn.cluster import AgglomerativeClustering
# TODO
# 計算每一群的個數
# TODO
# 找到 Speed 有遺漏值的兩隻寶可夢,並填入組內平均
# TODO
參考解答:
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import AgglomerativeClustering
from sklearn.neighbors import NearestNeighbors
data = pd.read_json('pokemon.json')
df = data.copy()
numerical_features = ['HP', 'Attack', 'Defense', 'SpecialAtk', 'SpecialDef']
X = df.loc[:, numerical_features]
ss = StandardScaler()
X_scaled = ss.fit_transform(X)
clt = AgglomerativeClustering(n_clusters=4, affinity='euclidean', linkage='ward')
clt.fit(X_scaled)
labels = pd.Series(clt.labels_, name='labels')
df_with_labels = pd.concat([df, labels], axis=1)
cluster_counts = df_with_labels['labels'].value_counts()
print(f"最小群個數: {min(cluster_counts)}")
print(f"最大群個數: {max(cluster_counts)}")
bylabels_speed_mean = df_with_labels.groupby('labels')['Speed'].mean()
nn_model = NearestNeighbors(n_neighbors=1, metric='euclidean')
nn_model.fit(X_scaled)
def predict_new_pokemon_speed(hp, attack, defense, specialatk, specialdef, ss_scaler, nn_predictor, labels_series, speed_means_by_label):
new_pokemon_data = pd.DataFrame([[hp, attack, defense, specialatk, specialdef]],
columns=numerical_features)
new_pokemon_scaled = ss_scaler.transform(new_pokemon_data)
distances, closest_indices = nn_predictor.kneighbors(new_pokemon_scaled)
closest_original_data_idx = closest_indices[0][0]
predicted_label = labels_series.loc[closest_original_data_idx]
predicted_speed = round(speed_means_by_label.loc[predicted_label])
return predicted_speed
pokemon1_speed_pred = predict_new_pokemon_speed(60, 48, 45, 43, 90, ss, nn_model, labels, bylabels_speed_mean)
print(f"寶可夢的Speed欄位值: {pokemon1_speed_pred}")
pokemon2_speed_pred = predict_new_pokemon_speed(70, 75, 60, 105, 60, ss, nn_model, labels, bylabels_speed_mean)
print(f"寶可夢的Speed欄位值: {pokemon2_speed_pred}")
程式解析
import pandas as pd # 導入 pandas 函式庫,用於資料處理和分析,特別是讀取 JSON 檔案和操作 DataFrame。
from sklearn.preprocessing import StandardScaler # 從 scikit-learn 的 preprocessing 模組導入 StandardScaler,用於特徵標準化。
from sklearn.cluster import AgglomerativeClustering # 從 scikit-learn 的 cluster 模組導入 AgglomerativeClustering,這是實現階層式分群的類別。
from sklearn.neighbors import NearestNeighbors # 從 scikit-learn 的 neighbors 模組導入 NearestNeighbors,用於尋找數據點的最近鄰居。
# 載入寶可夢資料
data = pd.read_json('pokemon.json') # 讀取名為 'pokemon.json' 的 JSON 檔案,將其內容載入到一個 pandas DataFrame 中,變數名為 data。
df = data.copy() # 建立 data DataFrame 的一個副本 (copy),將其賦值給 df,確保後續操作不會修改原始資料。
# 定義用於分群的數值特徵欄位
numerical_features = ['HP', 'Attack', 'Defense', 'SpecialAtk', 'SpecialDef'] # 定義一個列表,包含我們將用於分群的數值特徵名稱。
X = df.loc[:, numerical_features] # 從 df DataFrame 中選取所有行 (:),以及指定的數值特徵欄位,將它們作為特徵數據 (自變數) 賦值給 X。
# 特徵標準化
ss = StandardScaler() # 初始化一個 StandardScaler 物件。
X_scaled = ss.fit_transform(X) # 對選取的特徵數據 X 進行擬合 (fit) 和轉換 (transform)。這會將 X 中的數據標準化,使平均值為 0,標準差為 1。
# 利用階層式集群(Hierarchical clustering)進行分群
# n_clusters=4: 指定將數據分成 4 個群集。
# affinity='euclidean': 指定計算數據點之間距離的度量方法為歐幾里得距離。
# linkage='ward': 指定用於計算新形成群集之間距離的連結準則。'ward' 方法旨在最小化群集內部的方差。
clt = AgglomerativeClustering(n_clusters=4, affinity='euclidean', linkage='ward')
clt.fit(X_scaled) # 使用標準化後的特徵數據 X_scaled 訓練階層式分群模型。
# 計算並印出每個群集的元素個數
labels = pd.Series(clt.labels_, name='labels') # 從訓練好的模型中獲取每個數據點所屬的群集標籤 (clt.labels_),並將其轉換為一個 Pandas Series,命名為 'labels'。
df_with_labels = pd.concat([df, labels], axis=1) # 將分群標籤 Series (labels) 合併到原始 df DataFrame 中。axis=1 表示按列合併。
cluster_counts = df_with_labels['labels'].value_counts() # 計算每個群集標籤出現的次數,即每個群集的元素個數。
print(f"最小群個數: {min(cluster_counts)}") # 印出所有群集中元素數量最少的那個群的個數。
print(f"最大群個數: {max(cluster_counts)}") # 印出所有群集中元素數量最多的那個群的個數。
# 計算每個群集 'Speed' 欄位的平均值
bylabels_speed_mean = df_with_labels.groupby('labels')['Speed'].mean() # 根據 'labels' 欄位對 df_with_labels 進行分組,然後計算每個群組中 'Speed' 欄位的平均值。
# 建立 NearestNeighbors 模型,用於找出新數據點最接近的原始數據點
# n_neighbors=1: 設定尋找最近的一個鄰居。
# metric='euclidean': 指定使用歐幾里得距離來計算鄰居。
nn_model = NearestNeighbors(n_neighbors=1, metric='euclidean')
nn_model.fit(X_scaled) # 使用標準化後的原始數據 X_scaled 來訓練 NearestNeighbors 模型。該模型將用於查找新數據點的最近鄰居。
# 定義一個函數,用於預測新寶可夢的 Speed 欄位值
# 該函數模擬 AgglomerativeClustering 的 'predict' 行為,通過找到最近鄰居來推斷群組。
def predict_new_pokemon_speed(hp, attack, defense, specialatk, specialdef, ss_scaler, nn_predictor, labels_series, speed_means_by_label):
# 建立新寶可夢的DataFrame,包含其能力值
new_pokemon_data = pd.DataFrame([[hp, attack, defense, specialatk, specialdef]],
columns=numerical_features) # 確保欄位名稱與原始數據一致。
# 標準化新寶可夢的數據 (使用訓練時相同的 StandardScaler 物件)
new_pokemon_scaled = ss_scaler.transform(new_pokemon_data)
# 找出新寶可夢數據點在原始標準化數據中最接近的點的距離和索引
distances, closest_indices = nn_predictor.kneighbors(new_pokemon_scaled)
closest_original_data_idx = closest_indices[0][0] # 取得最近點在原始數據中的索引(因為只找一個鄰居,所以取第一個結果的第一個元素)。
# 根據最近點的索引,查找其在原始分群結果中歸屬的群組標籤
predicted_label = labels_series.loc[closest_original_data_idx]
# 根據推斷出的群組標籤,取得該群組的平均 Speed 值 (並四捨五入取整)
predicted_speed = round(speed_means_by_label.loc[predicted_label])
return predicted_speed # 返回預測的 Speed 值
# 處理能力值為 {"HP":60, "Attack":48, "Defense":45, "SpecialAtk":43, "SpecialDef":90} 的寶可夢
# 調用 predict_new_pokemon_speed 函數,並傳入該寶可夢的能力值及相關模型和數據。
pokemon1_speed_pred = predict_new_pokemon_speed(60, 48, 45, 43, 90, ss, nn_model, labels, bylabels_speed_mean)
print(f"寶可夢的Speed欄位值: {pokemon1_speed_pred}") # 印出預測的 Speed 值。
# 處理能力值為 {"HP":70, "Attack":75, "Defense":60, "SpecialAtk":105, "SpecialDef":60} 的寶可夢
# 調用 predict_new_pokemon_speed 函數,並傳入該寶可夢的能力值及相關模型和數據。
pokemon2_speed_pred = predict_new_pokemon_speed(70, 75, 60, 105, 60, ss, nn_model, labels, bylabels_speed_mean)
print(f"寶可夢的Speed欄位值: {pokemon2_speed_pred}") # 印出預測的 Speed 值。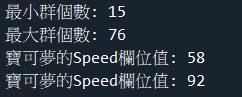
Yiru@Studio - 關於我 - 意如