文、意如

題目:
diabetes dataset是一個糖尿病的資料集,請撰寫程式,讀取此資料集的資料,建立線性複迴歸的預測模型,輸出均方誤差(mean_squared_error, MSE)及決定係數R2。
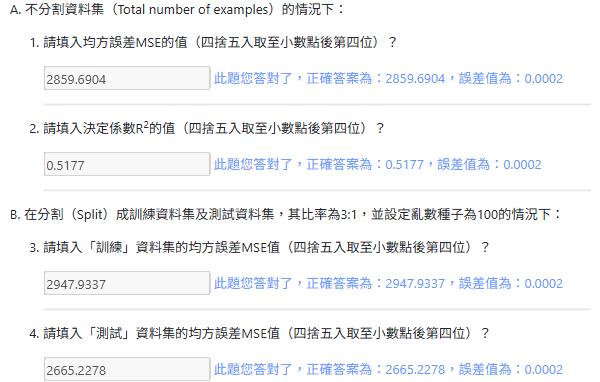
A. 不分割資料集(Total number of examples)的情況下:
1.請填入均方誤差MSE的值(四捨五入取至小數點後第四位)?
2.請填入決定係數R2的值(四捨五入取至小數點後第四位)?
B. 在分割(Split)成訓練資料集及測試資料集,其比率為3:1,並設定亂數種子為100的情況下:
3.請填入「訓練」資料集的均方誤差MSE值(四捨五入取至小數點後第四位)?
4.請填入「測試」資料集的均方誤差MSE值(四捨五入取至小數點後第四位)?
MLD03.py
from sklearn import datasets
import pandas as pd
from sklearn.linear_model import LinearRegression
# TODO
#get x
# TODO
#Total number of examples
# TODO
print('Total number of examples')
print('MSE=' )
print('R-squared=' )
#3:1 100
xTrain2, xTest2, yTrain2, yTest2=
lm2=LinearRegression()
lm2.fit( , )
# TODO
print('Split 3:1')
print('train MSE=' )
print('test MSE=' )
print('train R-squared=' )
print('test R-squared=' )
參考解答:
from sklearn import datasets
import pandas as pd
from sklearn.linear_model import LinearRegression
data = datasets.load_diabetes()
#get x
X = pd.DataFrame(data.data, columns=data.feature_names)
y = pd.Series(data.target)
#Total number of examples
model = LinearRegression()
model.fit(X, y)
y_pred = model.predict(X)
from sklearn.metrics import mean_squared_error
MSE = mean_squared_error(y, y_pred)
r2 = model.score(X, y)
print('Total number of examples')
print(f'MSE= {MSE:.4f}')
print(f'R-squared= {r2:.4f}')
#3:1 100
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1/4, random_state=100)
model2=LinearRegression()
model2.fit(X_train, y_train)
train_pred = model2.predict(X_train)
test_pred = model2.predict(X_test)
train_MSE = mean_squared_error(y_train, train_pred)
test_MSE = mean_squared_error(y_test, test_pred)
print('Split 3:1')
print(f'train MSE= {train_MSE:.4f}')
print(f'test MSE= {test_MSE:.4f}')
程式解析:
# 從 sklearn 載入內建資料集模組
from sklearn import datasets
# 載入 pandas,常用來操作表格資料
import pandas as pd
# 從 sklearn 載入線性回歸模型
from sklearn.linear_model import LinearRegression
# 載入糖尿病資料集(共 442 筆資料,10 個特徵)
data = datasets.load_diabetes()
# 將特徵資料轉成 DataFrame 格式(每列為一筆樣本,每欄為一個特徵)
X = pd.DataFrame(data.data, columns=data.feature_names)
# 將標籤(目標變數)轉成 pandas Series
y = pd.Series(data.target)
# 建立線性回歸模型
model = LinearRegression()
# 使用所有資料(X 和 y)來訓練模型
model.fit(X, y)
# 使用訓練後的模型來預測 X 中的目標變數
y_pred = model.predict(X)
# 載入 MSE(均方誤差)計算工具
from sklearn.metrics import mean_squared_error
# 計算模型在訓練資料上的 MSE
MSE = mean_squared_error(y, y_pred)
# 計算模型的 R-squared(決定係數),評估模型的解釋能力
r2 = model.score(X, y)
# 輸出標題
print('Total number of examples')
# 輸出 MSE(小數點後四位)
print(f'MSE= {MSE:.4f}')
# 輸出 R-squared(小數點後四位)
print(f'R-squared= {r2:.4f}')
# 從 sklearn 載入訓練/測試資料切分工具
from sklearn.model_selection import train_test_split
# 將資料切分為訓練集與測試集,比例為 3:1(test_size=1/4),設定亂數種子為 100
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1/4, random_state=100)
# 建立另一個線性回歸模型來對切分後的資料訓練
model2 = LinearRegression()
# 使用訓練資料訓練模型
model2.fit(X_train, y_train)
# 預測訓練資料的結果(用來評估訓練誤差)
train_pred = model2.predict(X_train)
# 預測測試資料的結果(用來評估泛化能力)
test_pred = model2.predict(X_test)
# 計算訓練資料的 MSE
train_MSE = mean_squared_error(y_train, train_pred)
# 計算測試資料的 MSE
test_MSE = mean_squared_error(y_test, test_pred)
# 輸出標題
print('Split 3:1')
# 輸出訓練資料的 MSE(小數點後四位)
print(f'train MSE= {train_MSE:.4f}')
# 輸出測試資料的 MSE(小數點後四位)
print(f'test MSE= {test_MSE:.4f}')

Yiru@Studio - 關於我 - 意如