文、意如
為什麼多執行緒在 CPU 密集任務中無法加速?
當你在 Python 中使用 threading(多執行緒)來執行計算任務時,你預期它能同時在 CPU 的多個核心上運行,從而加速。
但 GIL(全局解譯器鎖)的存在,會強制所有 Python 執行緒排隊,它們只能輪流執行。因此,在這個計算量大的範例中,多執行緒的總耗時會與單執行緒差不多,甚至更久(因為還有切換執行緒的額外開銷)。想像你的餐廳只有一個廚師(CPU 核心)和一個料理台(GIL 鎖)。
- 多執行緒 (Threading) 就像你雇用了 10 個幫手,但他們都必須擠在同一個料理台上輪流切菜、煮湯。由於料理台(GIL)限制,他們無法同時做飯,導致速度並沒有快 10 倍。
- I/O 任務 (網路/讀寫文件) 就像是「等快遞」——當一個幫手去等快遞時,他會禮貌地把料理台讓給別人,這時速度才會提升。
範例程式碼:
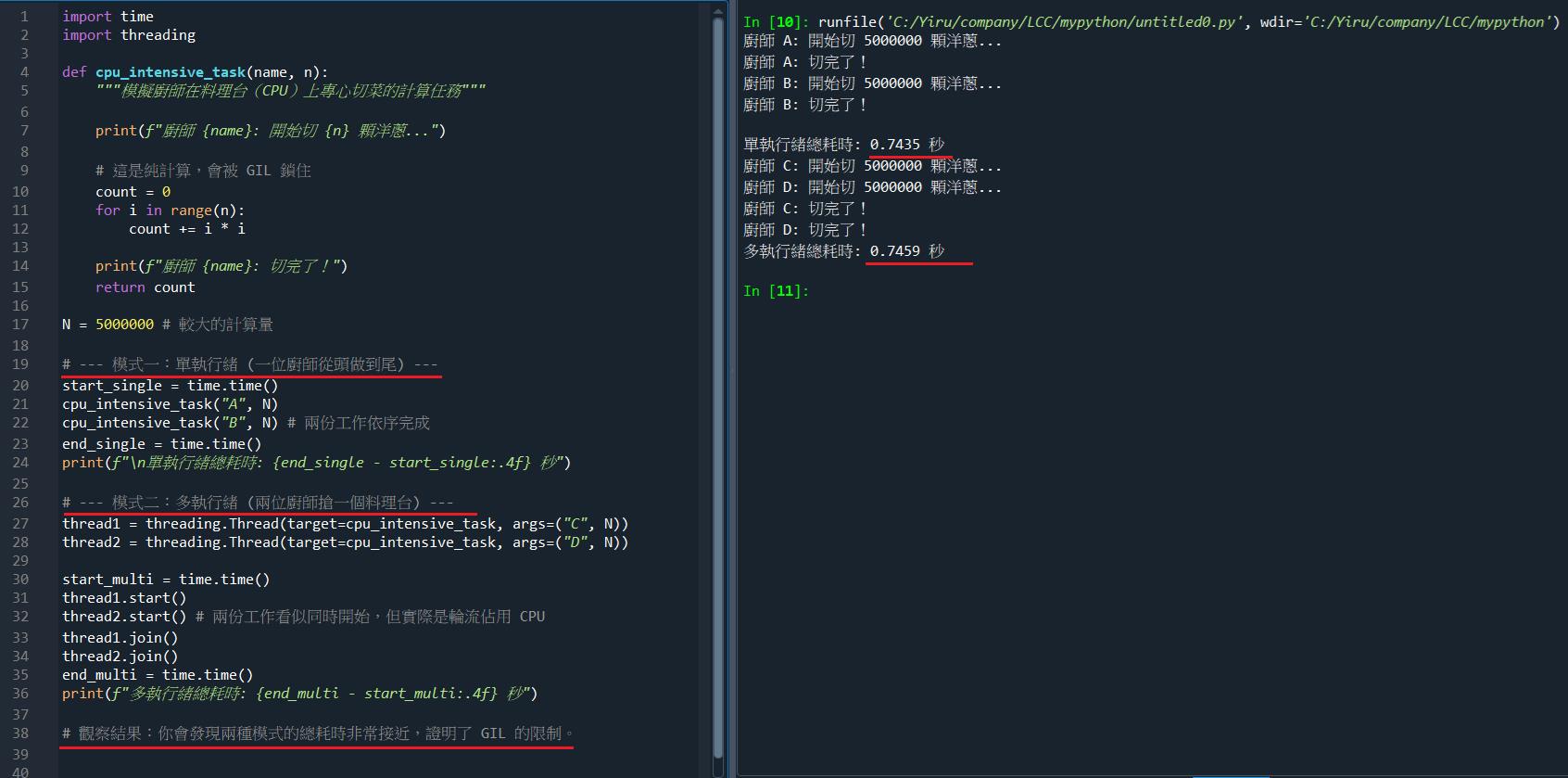
import time
import threading
def cpu_intensive_task(name, n):
"""模擬廚師在料理台(CPU)上專心切菜的計算任務"""
print(f"廚師 {name}: 開始切 {n} 顆洋蔥...")
# 這是純計算,會被 GIL 鎖住
count = 0
for i in range(n):
count += i * i
print(f"廚師 {name}: 切完了!")
return count
N = 5000000 # 較大的計算量
# --- 模式一:單執行緒 (一位廚師從頭做到尾) ---
start_single = time.time()
cpu_intensive_task("A", N)
cpu_intensive_task("B", N) # 兩份工作依序完成
end_single = time.time()
print(f"\n單執行緒總耗時: {end_single - start_single:.4f} 秒")
# --- 模式二:多執行緒 (兩位廚師搶一個料理台) ---
thread1 = threading.Thread(target=cpu_intensive_task, args=("C", N))
thread2 = threading.Thread(target=cpu_intensive_task, args=("D", N))
start_multi = time.time()
thread1.start()
thread2.start() # 兩份工作看似同時開始,但實際是輪流佔用 CPU
thread1.join()
thread2.join()
end_multi = time.time()
print(f"多執行緒總耗時: {end_multi - start_multi:.4f} 秒")
# 觀察結果:你會發現兩種模式的總耗時非常接近,證明了 GIL 的限制。
Yiru@Studio - 關於我 - 意如