最近跟同事在討論一個SQL效能的問題,
裡面有依查詢條件查出資料後,
再取前 20 筆的資料,可是才前20筆資料,
為什麼要花費很久的時間呢?

如上圖所示,雖然是只取出20筆的資料,
但因為在取這20筆之前需要依某個2個欄位排序才取出來。
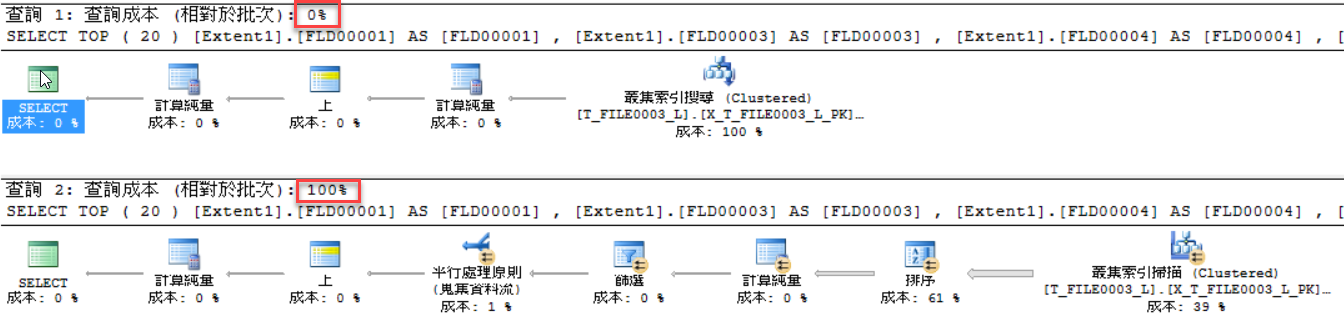
所以排序佔的比重為 61% 。
這裡有另一個重點是,資料很多,而且查出的資料也很多。
而且又要排序,所以 SQL 就直接使用平行處理 + Scan 來處理比較有效率,但成本比較高。
以下為 沒排序與排序 的成本比較,
想到以下幾個解法,
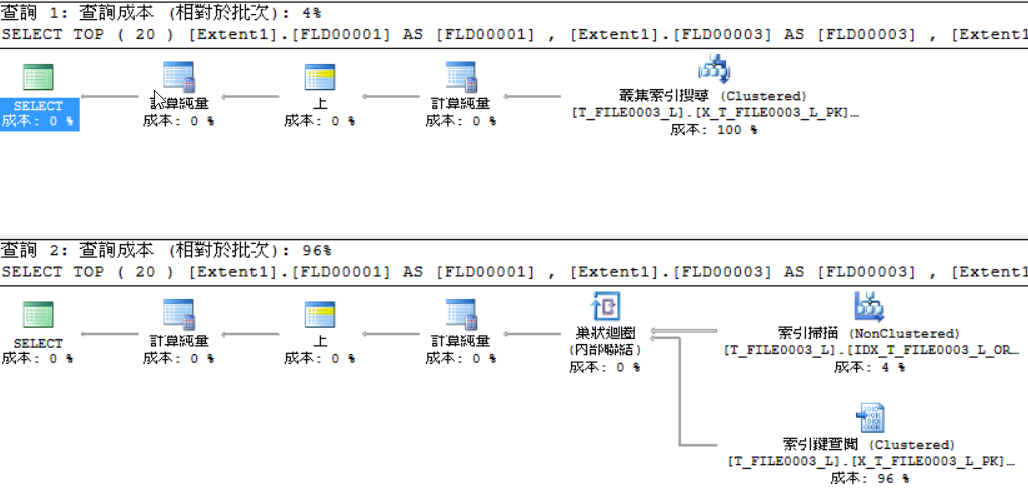
1.為那個排序的欄位加上index,查詢時就值接用那個 index 去找出 TOP 20 (在無法調整程式時的做法)。
與沒排序的成本相對增加了 4%,而且一開始找出來的資料變少了,如下,
2.增加查詢條件,減少查出的資料量 (建議解法)
以上面這個案例來看,總資料有 107,828 筆,而查出的資料有 61,688 筆。
應該要讓 User 查詢他真正想要的資料,而不是查詢出一堆來讓 User 肉眼再 Search 一次。
如果有類似狀況的朋友,可以參考看看哦!
Hi,
亂馬客Blog已移到了 「亂馬客 : Re:從零開始的軟體開發生活」
請大家繼續支持 ^_^
