最近 Cloud Computing 的幾個指標性的供應商,包含 Microsoft, Amazon, Google 等,都相繼提出了邊界運算 (又稱邊際運算) 的概念,其實說穿了,只是分久必合,合久必分的循環而己。
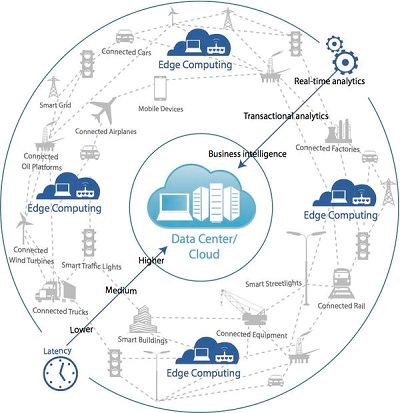 (Source: https://www.promptcloud.com/blog/big-data-processing-edge-computing)
(Source: https://www.promptcloud.com/blog/big-data-processing-edge-computing)
先來說明一下什麼叫邊界運算吧。
這兩年,Machine Learning 以及 Big Data 的極速發展,使得很多基於資料科學 (Data Science) 所找出來的大量模式 (Model, 或是 Pattern) 都保存於 Cloud Computing 的機房,雖然能經由 Cloud Computing 獲得資料分析的結果,但是 Cloud Computing 的各大資料中心還是放在固定的地理位置,例如人在台灣,資料分析卻要送到美國,難以避免的網路延遲仍舊存在,雖然各大供應商都盡力在擴建資料中心,但資料中心的選址、政治問題與成本考量,無法像是小規模的機房那樣快速,別忘了一座可用在 Cloud Computing 的資料中心需要至少半年以上的時間,但商業運用需要的是快速,尤其是花費大量資源所找出來的模式,即便變成了 Web Service 或 Web API 供資料分析使用,然而仍無法免除網路延遲。
兩年前,有一個稱為霧運算 (Fog Computing) 的概念衍生出來了,也就是把運算能力下放到 IoT 的設備,然而兩年前 Machine Learning 需要的運算能力不是一個 IoT 的設備就能處理的,因此霧運算當時並沒有受到重視,不過科技的進步神速,每年都有更好的硬體出來,例如樹苺派這兩年從 RP1 進步到 RP3,升級了運算能力,已經開始能具備終端級 (end-point) 的資料分析能力,只是現在還是沒辦法處理一些高階分析。
既然還是無法由 IoT 直接分析,又不想要增加太多的網路傳輸負載,因此就有供應商開始思考,有沒有辦法將這些資料分析的模式下放給離資料收集器 (即資料來源) 更近一點的節點,讓資料分析的速度能加快,基於統計學上的常態分配理論,大多數穩定的分析模型都有至少 95% 的信心水準,足以支撐一般商業上所需的資料分析。其實這概念就像 CDN (內容散布網路) 一樣,將資料移到離使用者近的節點,使用者獲得資料的時間就縮短了,將這個概念套用到運算上,就形成了邊界運算的概念。
邊界運算最典型的一個用法就是 Microsoft 的 Cognitive Service,它是基於 Azure 的 Machine Learning 所打造的智慧式資料分析模式,在開發模式的期間,需要用雲端的大量運算能力,當模式的信心水準愈來愈高時,它只是要作為後續資料的分析之用,而不用從頭來打造,需要的資料分析運算資源就隨之下降,如果我只需要在離資料來源較近的地方建置一個網路節點 (也就是邊界),提供足以執行 Cognitive Service 資料分析模型的運算能量,那麼要用 Cognitive Service 分析資料的服務就不用再將資料送到雲端,只要送到支援 Cognitive Service 的運算邊界就能得到分析結果,省去了額外的網路傳輸的時間成本,縮短了得到結果的時間,進一步的加快商業運用的速度。
因此,邊界運算適用的正是現在熱頭上的即時分析 (Realtime Analytics),例如車載運算、工業級數據分析等需要在極短時間內獲得成果的運算需求,只要利用雲端運算執行大數據分析與 Machine Learning 獲得穩定可信賴的模式後,在就近的地方就能即時分析資料並獲取結果,正是邊界運算的優勢。
不過,能不能玩邊界運算,得看資料模式需要的運算能量要多大,即使是簡單的資料分析模式,也還是有可能需要大量 CPU/GPU 的處理,成本還是存在。同時,即便有了邊界運算,那 5% 的離峰值或變異值,仍舊需要 Cloud Computing 來處理並演進分析模型,這樣的不斷循環才能讓資料模型更貼近更符合需求與必要的精確度。
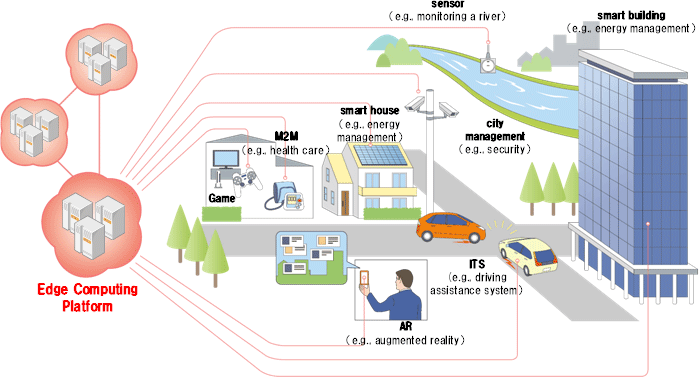 (Source: http://www.ntt.co.jp/news2014/1401e/140123a.html)
(Source: http://www.ntt.co.jp/news2014/1401e/140123a.html)
Reference: https://en.wikipedia.org/wiki/Edge_computing