之前我寫了一篇 [SQL SERVER]了解制式範圍和混和範圍提到tempdb資源競爭問題,
去年參加SQL PASS年終聚會時,剛好有朋友詢問我當時如何發現該問題,這篇就來記錄整個過程。
有那些操作或功能會使用tempdb空間
1 Order by、distinct、group by、hash和spool操作
2 Query
3 Triggers
4 Snapshot isolation and read committed snapshot (RCSI)
5 MARS
6 Online index create or rebuild
7 Use Temporary tables, table variables, and table-valued functions
8 DBCC CHECK
9 LOB parameters
10 Cursors
11 Service Broker and event notification
12 XML and LOB variables
13 Query notifications
14 Database mail
15 User-defined functions
可以看到很多一般操作和功能都會使用到tempdb資源,所以一般來說tempdb是相當忙碌的,所以好好管理tempdb真的相當重要。
Note: Tempdb分3種物件使用量,使用者、內部和版本存放區。
什麼是tempdb I/O分配瓶頸
多核心環境下,當並行連線數量多且使用tempdb資源時(如建立temp table、drop temp table、work table..等),
新增資料至temp table時,這時候PFS(page free space)、GAM(global allocation map)和SGAM(share global allocation map)都必須變更相關資訊,
SQL Server會在這些頁面上使用SH和Update的latches來維持內部資料一致性(由於是記憶體中的操作,所以過程相當短暫),
因預設分配混和範圍,並行性高系統這時有很大機會發生latch上的競爭衝突(因大家都在搶相同資源)。
如何確認tempdb有I/O分配瓶頸
我個人是使用擴充事件來監控,沒用過的朋友可以參考我以前寫的文章
[SQL SERVER][Maintain]擴充的事件(1)
[SQL SERVER][Maintain]擴充的事件(2)
[SQL SERVER][Maintain]監控Deadlock
使用擴充事件監控,我們要監控sqlos所發生的資源等待事件
--Find the event name allows to look at wait statistics
select xo.name,object_type,xo.[description]
from sys.dm_xe_objects xo INNER JOIN sys.dm_xe_packages xp
on xp.[guid] = xo.[package_guid]
where xo.[object_type] = 'event' AND xo.name LIKE '%wait%'
order by xp.[name];
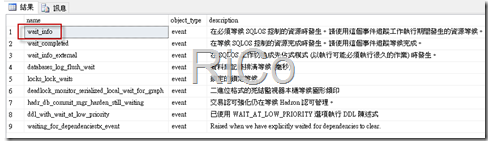
下面我會將相關資訊使用非同步方式寫入File來減少Server資源開銷但需注意硬碟空間使用量
--Drop the event if it already exists
DROP EVENT SESSION Monitor_wait_info_tempdb ON SERVER;
GO
--Create the event
CREATE EVENT SESSION Monitor_wait_info_tempdb ON SERVER
ADD EVENT sqlos.wait_info
(
--Add additional columns to track
ACTION (sqlserver.database_id, sqlserver.sql_text, sqlserver.session_id, sqlserver.tsql_stack)
WHERE sqlserver.database_id = 2 --filter database id = 2 i.e tempdb
--This allows us to track wait statistics at database granularity
) --As a best practise use asynchronous file target, reduces overhead.
ADD TARGET package0.asynchronous_file_target(
SET filename='E:\sqlextenevent\Monitor_wait_info_tempdb.etl'
, metadatafile='E:\sqlextenevent\Monitor_wait_info_tempdb.mta')
GO
--start the session
ALTER EVENT SESSION Monitor_wait_info_tempdb ON SERVER
STATE = START;
GO
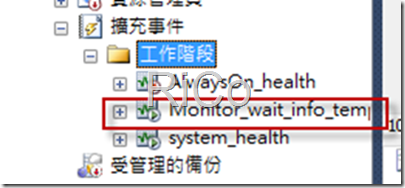
模擬tempdb I/O分配瓶頸(多條session同時執行)
--using table variables, temp tables, temp tables with named constraints
declare @test1 TABLE (c1 INT NOT NULL, c2 datetime)
INSERT @test1 SELECT 1, GETDATE()
--drop table #test1
GO 1000
CREATE TABLE #test1 (c1 INT NOT NULL, c2 datetime)
INSERT #test1 SELECT 1, GETDATE()
DROP TABLE #test1
GO 1000
CREATE TABLE #test1 (c1 INT NOT NULL, c2 datetime, CONSTRAINT pk_test PRIMARY KEY CLUSTERED(c1))
INSERT #test1 SELECT 1, GETDATE()
DROP TABLE #test1
GO 1000
查詢相關等待資訊
SELECT wait_typeName
, SUM(total_duration) AS total_duration
, SUM(signal_duration) AS total_signal_duration
FROM (
SELECT
FinalData.R.value ('@name', 'nvarchar(50)') AS EventName,
FinalData.R.value ('data(data/value)[1]', 'nvarchar(50)') AS wait_typeValue,
FinalData.R.value ('data(data/text)[1]', 'nvarchar(50)') AS wait_typeName,
FinalData.R.value ('data(data/value)[3]', 'int') AS total_duration,
FinalData.R.value ('data(data/value)[4]', 'int') AS signal_duration,
FinalData.R.value ('(action/.)[1]', 'nvarchar(50)') AS SessionID,
FinalData.R.value ('(action/.)[2]', 'nvarchar(max)') AS SQLText,
FinalData.R.value ('(action/.)[3]', 'nvarchar(50)') AS DatabaseID
FROM
( SELECT CONVERT(xml, event_data) AS xmldata
FROM sys.fn_xe_file_target_read_file
('E:\sqlextenevent\Monitor_wait_info_tempdb*.etl', 'E:\sqlextenevent\Monitor_wait_info_tempdb*.mta', NULL, NULL)
) AsyncFileData
CROSS APPLY xmldata.nodes ('//event') AS FinalData (R)) xyz
WHERE --wait_typeName like 'page%'
wait_typeName NOT IN ('SLEEP_TASK')
GROUP BY wait_typeName
ORDER BY total_duration
GO
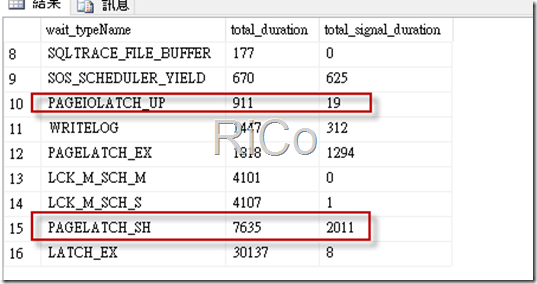 這裡顯示tempdb相關等待資訊,可以看到存在I/O分配瓶頸。
這裡顯示tempdb相關等待資訊,可以看到存在I/O分配瓶頸。
如何減少tempdb 資源競爭並優化
*建立多data file。我自己一般會建立CPU core數量的1/2或1/4,但該數量不可超過cpu core數量或8。
*啟用trace flag 1117和1118。如果建立多data file還是無法有效減少tempdb資源競爭的話,那麼啟用trace flag 1117和1118會有不錯的改善。
*避免產生過多I/O。相關查詢請確認都使用正確索引(index seek),可參考[SQL SERVER][TSQL]獲取各種高成本查詢語法 找出高成本I/O TSQL,並進行優化作業。
*合理的檔案初始大小和自動成長大小。過大的成長大小可能導致timeout,過小的成長大小將有更多碎片,所以需依環境取得一個平衡。
如何壓縮tempdb空間大小
目前聽到大部分都是使用restart sql service方法來減少tempdb所使用空間,因為重新啟動會建立新的tempdb(會參考model某些設定),但我個人實務上很少這樣處理,我建議使用 DBCC SHRINKFILE來壓縮相關檔案大小。
--壓縮tempdb交易紀錄檔案大小
DBCC SHRINKFILE('templog', TRUNCATEONLY )--截斷交易紀錄檔
DBCC SHRINKFILE('templog', 500 )--500mb
--壓縮tempdev 檔案大小
DBCC SHRINKFILE('tempdev', 1000 )--1000mb
參考
[SQL SERVER][Memo] tempdb datafile該切多少份?
SQL Server Tempdb Usage and Bottlenecks tracked with Extended Events
[SQL SERVER][Performance] tempdb 優化
Monitoring tempdb space usage and scripts for finding queries which are using excessive tempdb space