誰說Like '%rico%'沒辦法使用IndexSeek。
去年我在SQL PASS分享如何提高FullScan效能,Relational Database大致上最有效的方法就是強制使用平行計畫(參考[SQL SERVER]讓一般使用者執行DBCC TraceON),但資料量小且多核心環境下,要留意不正當平行操作的效能影響,另一方法我個人是使用NoSQL Database來改善,現實世界中,系統有時無可避免FullScan,好比使用者要求 Like ‘%12%’之類的查詢,所以前端我會判斷使用者所輸入欄位並決定要使用那個資料庫(SQL Server or NoSQL Database)。
這篇我來分享如何讓Like ‘%12%’這類的語法使用index seek,當然如你有聽過我去年在SQL PASS效能調校分享的話,我這方法其實真的很簡單。
針對以下TSQL建立正確nonclustered index
SELECT c1, c2, AString
FROM dbo.BigTestLIKE
WHERE AString LIKE '%98%';
create index idx1 ON dbo.BigTestLIKE(AString);
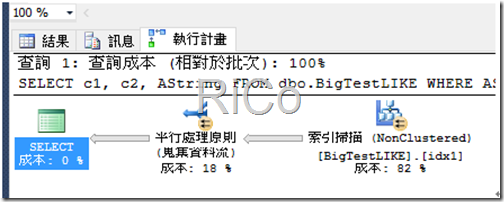 (70000 個資料列受到影響)
(70000 個資料列受到影響)
掃描計數 3,邏輯讀取 12058
CPU 時間 = 1093 ms,經過時間 = 1439 ms
因為B-tree先天限制,所以執行計畫使用索引掃描是可以預期並理解,那有沒有辦法使用索引搜尋呢?
答案是有的,而且方法很簡單。
修改TSQL
SELECT c1, c2, AString
FROM dbo.BigTestLIKE
WHERE AString LIKE '%98%' and AString>''
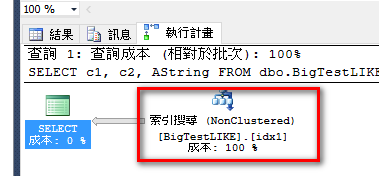
(70000 個資料列受到影響)
資料表 'BigTestLIKE'。掃描計數 1,邏輯讀取 6725
CPU 時間 = 797 ms,經過時間 = 1075 ms
增加條件 AString>'' 讓其符合SARG格式,執行計畫則使用索引搜尋並大大降低I/O,效能調校就是這樣簡單。