之前我寫過一篇使用In-memory table variables來提高交易效能,這篇記錄當時一些額外測試。
不管是In-Memory table或table type都需要有一個索引,In-Memory index目前只有兩種(hash or range),
下面我針對batch insert進行一些簡單測試,至於為什麼我只測試batch insert,
因為我建議能batch insert就不要while loop insert,while loop insert大部分效能較差(無論是在AP或DB)。
note:clustered columnstore也是。
Hash index or Range index for Table Types
CREATE TYPE dbo.TVPHash AS TABLE
(
c1 INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1024) --500000
)
WITH (MEMORY_OPTIMIZED = ON);
CREATE TYPE dbo.TVPRange AS TABLE
(
c1 INT NOT NULL PRIMARY KEY NONCLUSTERED
)
WITH (MEMORY_OPTIMIZED = ON);
--batch insert
declare @myTVPhash dbo.TVPHash
insert into @myTVPhash
select top 500000 SalesOrderDetailID from SalesOrderDetailRico
go
declare @myTVPRange dbo.TVPRange
insert into @myTVPRange
select top 500000 SalesOrderDetailID from SalesOrderDetailRico
go
 Note:下面的while loop insert 最好還是不要在production執行
Note:下面的while loop insert 最好還是不要在production執行
declare @max int=500,@i int=1;
declare @myTVPhash dbo.TVPHash
begin tran
while(@i<=@max)
begin
insert into @myTVPhash
select SalesOrderDetailID from SalesOrderDetailRico
where SalesOrderDetailID=@i
ORDER BY SalesOrderDetailID
OFFSET (@i*1000) ROWS
FETCH NEXT 1000 ROWS ONLY;
set @i=@i+1;
end
commit
Hash index or Range index for In-Memory Table(schema_data)
Create table dbo.InMemoryHash
(
c1 INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1024)
)
WITH (MEMORY_OPTIMIZED = ON);

Create table dbo.InMemoryRange
(
c1 INT NOT NULL PRIMARY KEY NONCLUSTERED
)
WITH (MEMORY_OPTIMIZED = ON);
 Note:delete效能dbo.InMemoryRange也是優於dbo.InMemoryHash
Note:delete效能dbo.InMemoryRange也是優於dbo.InMemoryHash
Hash index or Range index for In-Memory Table(schema_only)
Create table dbo.InMemoryHashSchema
(
c1 INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1024)
)
WITH (MEMORY_OPTIMIZED = ON,DURABILITY = schema_only);
insert into dbo.InMemoryHashSchema
select top 500000 SalesOrderDetailID from SalesOrderDetailRico
go

Create table dbo.InMemoryRangeSchema
(
c1 INT NOT NULL PRIMARY KEY NONCLUSTERED
)
WITH (MEMORY_OPTIMIZED = ON,DURABILITY = schema_only);
insert into dbo.InMemoryRangeSchema
select top 500000 SalesOrderDetailID from SalesOrderDetailRico
go

結果: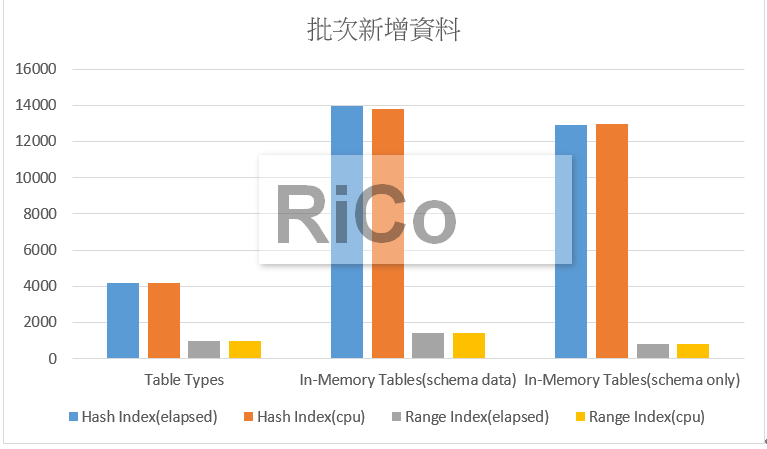 批次新增資料至暫存(中繼)資料表,優先考慮使用 Table type or schema_only with range index(Insert效能高,CPU資源低),
批次新增資料至暫存(中繼)資料表,優先考慮使用 Table type or schema_only with range index(Insert效能高,CPU資源低),
因為bucket_count大小會影響批次新增效能,且又固定記憶體大小且佔用(每一個bucket 占用 8 bytes),
所以決定bucket_count是相當重要的一件事,太小影響batch insert效能,太大又浪費記憶體資源。
下面,我將bucket_count設定500000,在來看看批次新增效能
Table types

In-Memory Tables(schema data)
ALTER TABLE dbo.InMemoryHash
ALTER INDEX PK__InMemory__3213663A2AE3E379
REBUILD WITH (BUCKET_COUNT = 500000);

In-Memory Tables(schema only)
 結果
結果
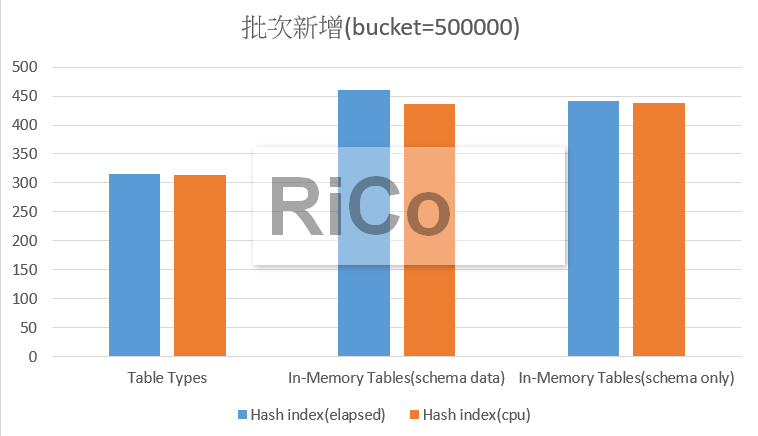 針對批次新增,你可以看到設定正確的bucket_count對新增效能的影響(最大450ms就把50萬筆資料新增完成),
針對批次新增,你可以看到設定正確的bucket_count對新增效能的影響(最大450ms就把50萬筆資料新增完成),
但實務上我個人還是會優先考量Rnage index,如果你的索引鍵值重複太高(平均超過10),請考慮Range。
DECLARE @allValues float(8) = 0.0, @uniqueVals float(8) = 0.0;
SELECT @allValues = 500000
SELECT @uniqueVals = Count(*) FROM
(SELECT DISTINCT top 500000 SalesOrderDetailID
FROM SalesOrderDetailRico) as d;
-- If (All / Unique) >= 10.0, use a nonclustered index, not a hash.
SELECT Cast((@allValues / @uniqueVals) as float) as [All_divby_Unique];
go
另外,我們也可以使用sys.dm_db_xtp_hash_index_stats來監看hash的統計資訊,並進行索引調整
SELECT
QUOTENAME(SCHEMA_NAME(t.schema_id)) + N'.' + QUOTENAME(OBJECT_NAME(h.object_id)) as [table],
i.name as [index],
h.total_bucket_count,
h.empty_bucket_count,
FLOOR((
CAST(h.empty_bucket_count as float) /
h.total_bucket_count) * 100)
as [empty_bucket_percent],
h.avg_chain_length,
h.max_chain_length
FROM
sys.dm_db_xtp_hash_index_stats as h
JOIN sys.indexes as i
ON h.object_id = i.object_id
AND h.index_id = i.index_id
JOIN sys.memory_optimized_tables_internal_attributes ia ON h.xtp_object_id=ia.xtp_object_id
JOIN sys.tables t on h.object_id=t.object_id
WHERE ia.type=1
ORDER BY [table], [index];
 平均chain長度=1最理想(不建議超過10),如果empty_bucket_percent>10%(標準門檻=33%),
平均chain長度=1最理想(不建議超過10),如果empty_bucket_percent>10%(標準門檻=33%),
且Chain長度>10,那麼就說明不適合建立hash index,
最理想狀態為empty_bucket_percent>33% 且Chain長度=1。
參考