Azure Machine Learning 因為其提供了近乎無限的雲端運算能力,在歐美先進國家已經有許多生技醫藥公司,應用這個產品在基因工程、製藥研發…等重要生產過程,成功地縮短上市時間,創造莫大的獲利空間。
所以本篇將以微軟的機器學習雲端產品,以決策樹與羅吉斯廻歸的演算法,針對銀行的範例資料進行 Classification分類,找出客戶對於行銷活動的關鍵因素。說得較技術,就是為了達成「購買回應」的預測,將會以類別變數作為輸出變數,透過數據模型,產出分類結果預測機率!

前言:
科學家不斷地致力於利用電腦的運算能力協助人類做決策,從Statistical analysis到Artificial intelligence;
我們聽過了IBM超級電腦在益智問答節目贏過其他參賽者拿到冠軍,我們聽過了啤酒尿布在Data mining的應用;
再到Machine learning,電腦透過各種樣本與案例學習不斷精進其模型,再配合適當的參數調整來協助人類,進行問題探索與預測分析,我們聽過Siri如何讓我們生活更便利;
再到Deep learning,電腦更可以自動最佳化參數來達到問題探索與預測分析的目的,所以我們聽到了AlphaGo電腦在圍棋比賽贏過韓國棋士,目前排行世界第五名。(2018更新:起初先是 AlphaGo 拿下了圍棋的世界第一,然後又推出了更厲害的AlphaGo Zero又以100比0局的成績,把圍棋的棋藝提升到更高的層次)
國際上都怎麼做?
根據CRISP-DM 國際資料組織對於資料採礦的定義,其流程應包含以下:
1、定義商業問題(Business Understanding)
2、定義分析資料(Data Understanding)
3、資料預處理(Data Preparation)
4、建立模型(Modeling)
5、評估模型(Evaluation)
6、應用模型(Deployment)
Microsoft Azure Machine Learning的特色:
1、平行運算,讓等待時間由幾天到一週變成幾分鐘到一個小時(參考值還是要視真正的資料量)
2、瀏覽器介面,不需安裝程式,永遠保持最新版本
3、類似SSIS的設計界面,透過GUI的拖拉點選,即可設計、執行與發佈
4、產出Web service的結果,讓資料模型可以在世界上任何角落的使用者被呼叫、被使用
5、自動產出說明文件(Preview功能)
在微軟的平台上要如何開始?
1. 登入Azure portal,建立一個Azure Machine Learning的工作區
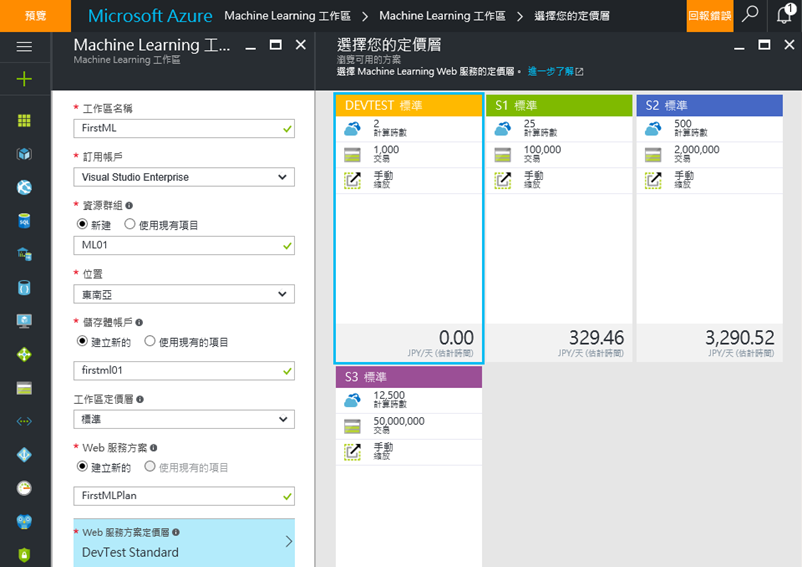 2. 大約1分鐘就可以建立好,再點選 Machine Learning Studio,就可以用瀏覽器開工了
2. 大約1分鐘就可以建立好,再點選 Machine Learning Studio,就可以用瀏覽器開工了
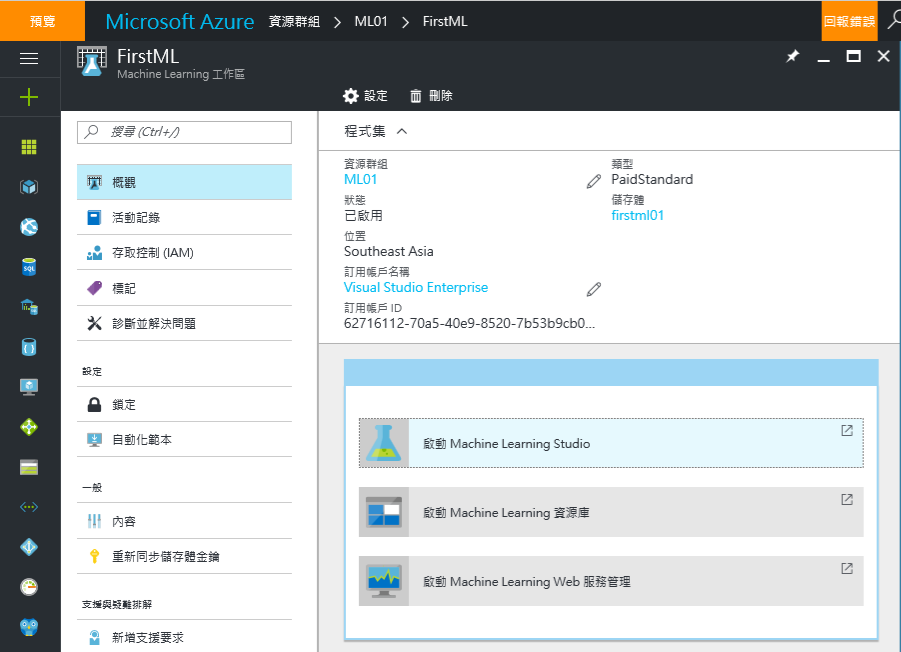 3. 要先登入才能進入剛才建立的工作區
3. 要先登入才能進入剛才建立的工作區 4. 你可以參考微軟提供的範例,在本篇是選擇使用空白 Experiment開始,所以按下Blank Experiment
4. 你可以參考微軟提供的範例,在本篇是選擇使用空白 Experiment開始,所以按下Blank Experiment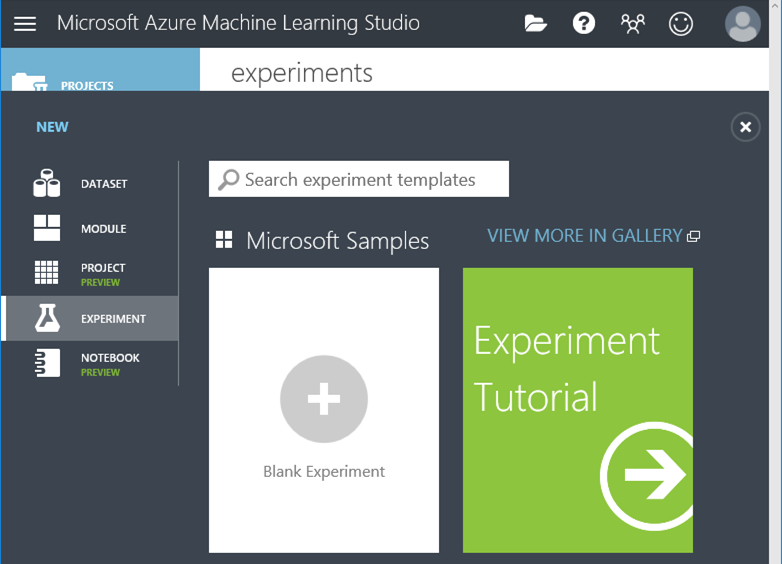 5. 可以開始拖拉左邊的元件了
5. 可以開始拖拉左邊的元件了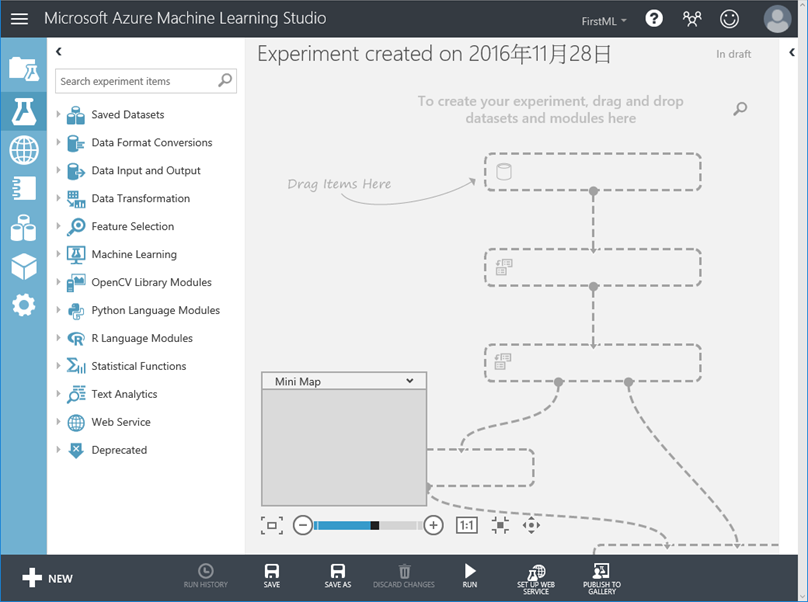 6. 先把範例資料匯入吧!
6. 先把範例資料匯入吧!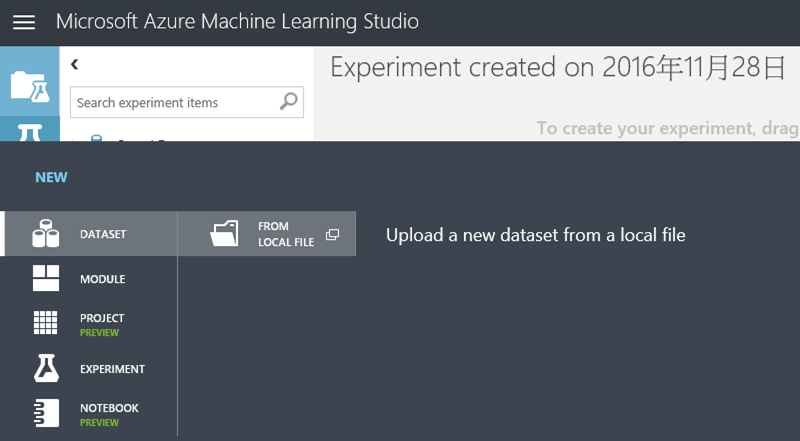 7. 當下方的綠色文字顯示已上傳成功,在左邊的Menu就會看到 My Datasets可以被拖拉
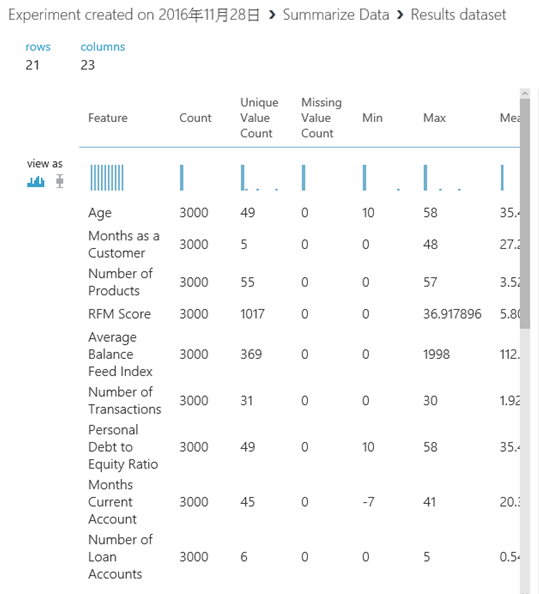
7. 當下方的綠色文字顯示已上傳成功,在左邊的Menu就會看到 My Datasets可以被拖拉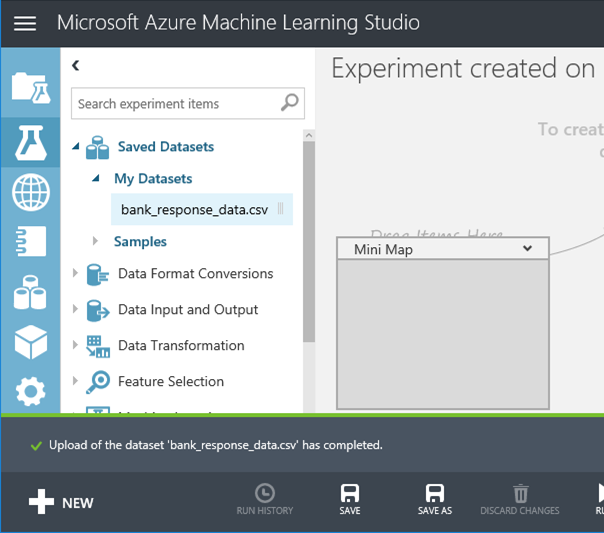 8. (非必要)若想要了解一下資料集的特性,可以拉一個Summarize Data,並按下Run或Run select(執行當前選取的元件)
8. (非必要)若想要了解一下資料集的特性,可以拉一個Summarize Data,並按下Run或Run select(執行當前選取的元件)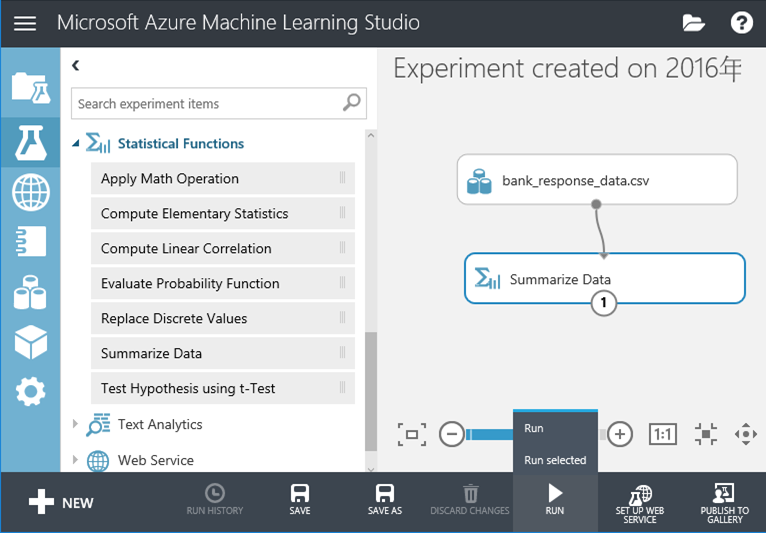 9. 執行成功後,對著Summarize Data的元件按右鍵,選擇Visualize即可檢視資料特性
9. 執行成功後,對著Summarize Data的元件按右鍵,選擇Visualize即可檢視資料特性
 10. 訓練資料與測試資料的抽樣比例以及選擇較近還是較遠的資料?是一門大學問,這裡先不深究
10. 訓練資料與測試資料的抽樣比例以及選擇較近還是較遠的資料?是一門大學問,這裡先不深究
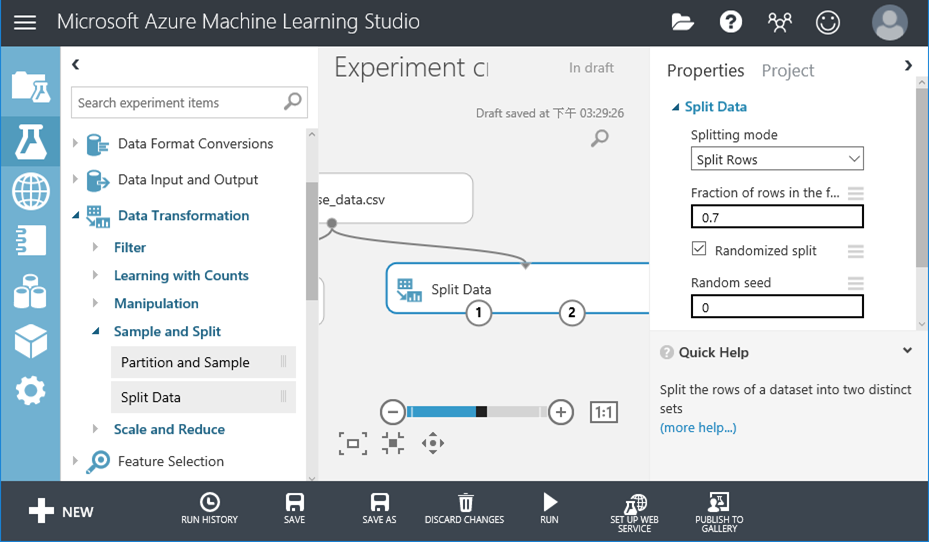
 11. 在右邊的參數視窗決定訓練資料與測試資料的比例,在本篇是7:3
11. 在右邊的參數視窗決定訓練資料與測試資料的比例,在本篇是7:3
 12. 建模之前要先過濾無意義的欄位,以及浪費運算資源,所以拉一個 Select Comlumns in Dataset元件
12. 建模之前要先過濾無意義的欄位,以及浪費運算資源,所以拉一個 Select Comlumns in Dataset元件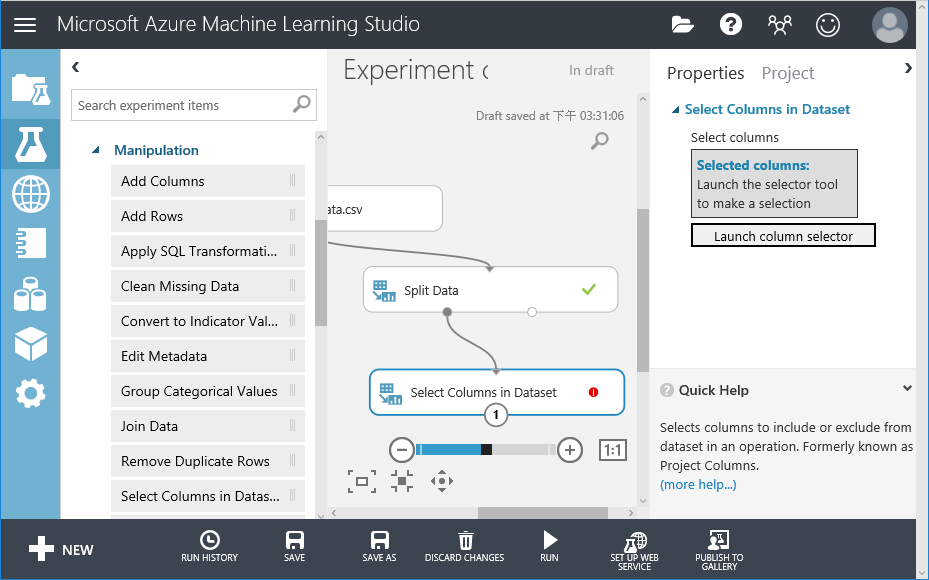 13. 過濾CustomerID與CampaignID
13. 過濾CustomerID與CampaignID
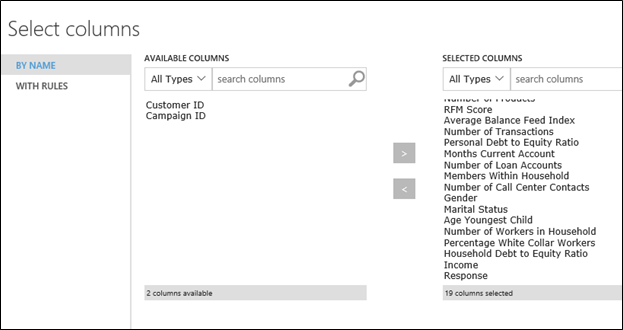 14. 有一個牛奶花生的廣告說「花生是電腦挑的」另人印象深刻電腦的強大功能,同理我們也可以讓電腦幫忙挑出有用的欄位當變數,怎麼做呢?只要把 Filter Based Feature Selected 元件拉進來
14. 有一個牛奶花生的廣告說「花生是電腦挑的」另人印象深刻電腦的強大功能,同理我們也可以讓電腦幫忙挑出有用的欄位當變數,怎麼做呢?只要把 Filter Based Feature Selected 元件拉進來
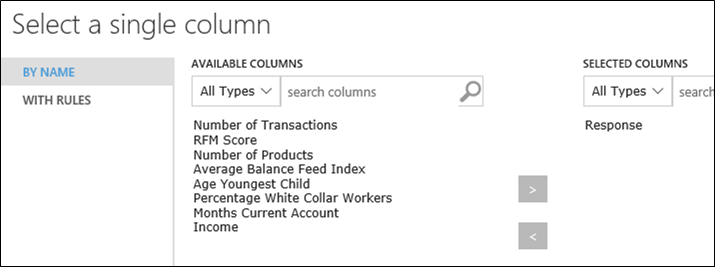
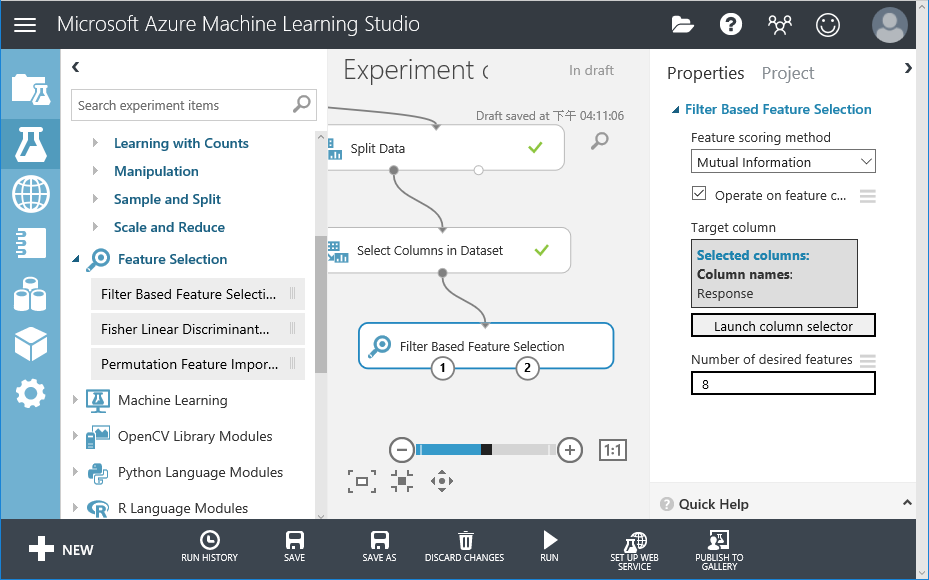 15. 選擇 Response做為標的欄位,以及數量為8,電腦會幫我們挑出適合做為變數的欄位
15. 選擇 Response做為標的欄位,以及數量為8,電腦會幫我們挑出適合做為變數的欄位
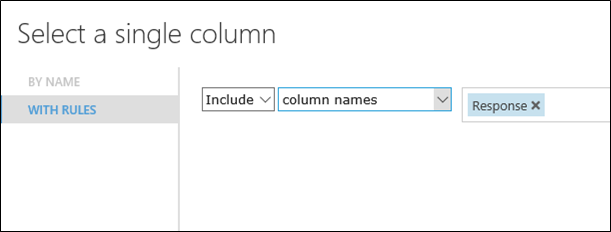
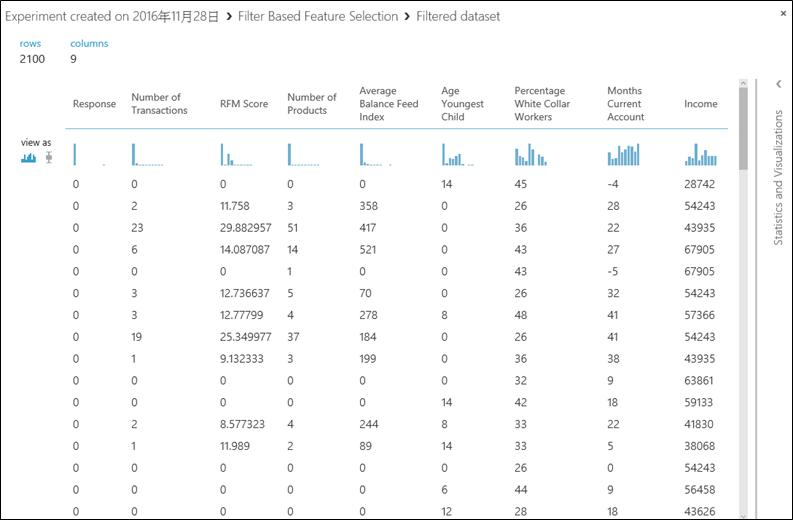
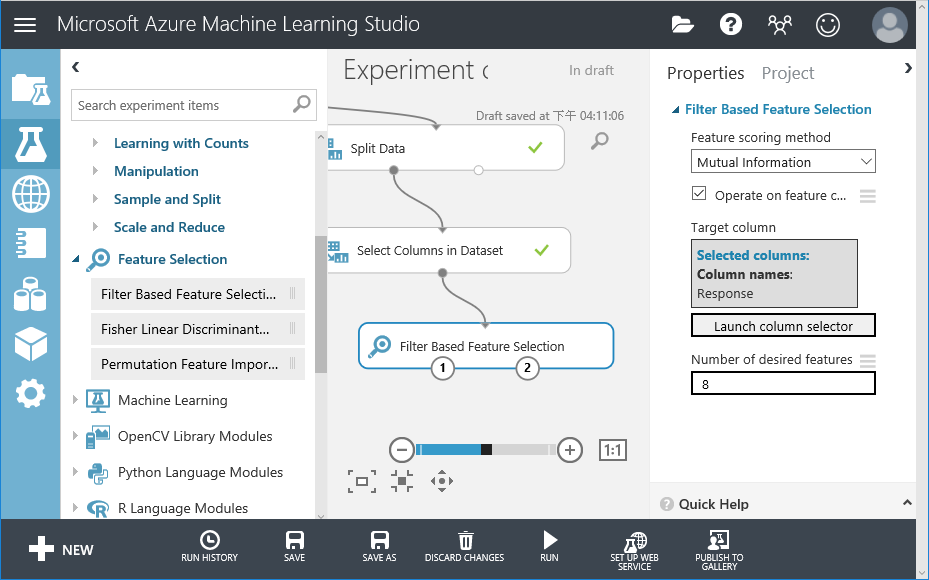 16. 執行後,電腦挑選出8個再加上Response,所以畫面上Column會等於9
16. 執行後,電腦挑選出8個再加上Response,所以畫面上Column會等於9
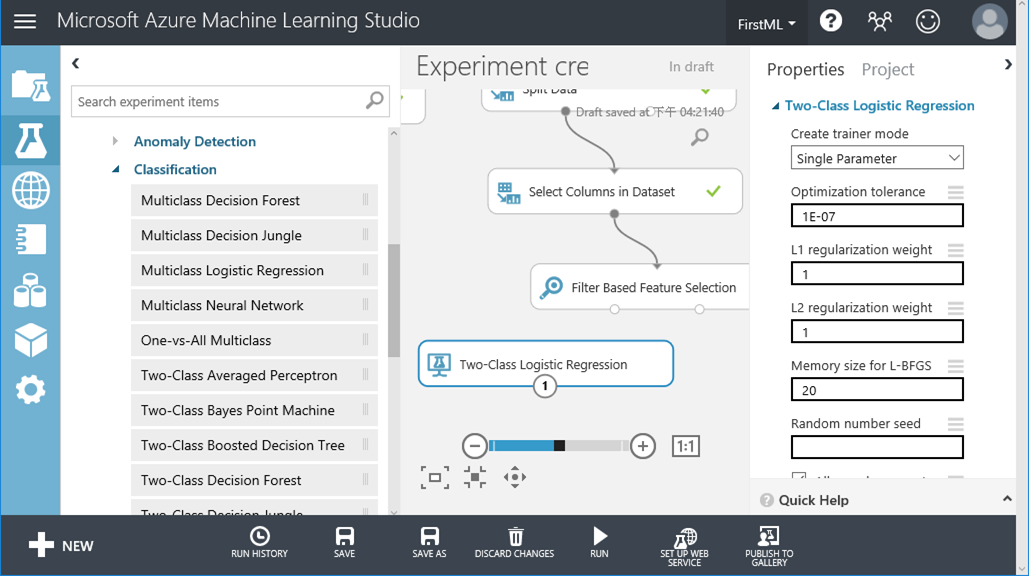
 17. 一般來說,資料科學家除了會評估模型的好壞也會同時評估哪個演算法會有更好的預測結果,而平行運算讓我們的時間成本變的更低!本篇除了決策樹,還會將傳統的羅吉斯廻歸統計方法加入比較。
17. 一般來說,資料科學家除了會評估模型的好壞也會同時評估哪個演算法會有更好的預測結果,而平行運算讓我們的時間成本變的更低!本篇除了決策樹,還會將傳統的羅吉斯廻歸統計方法加入比較。
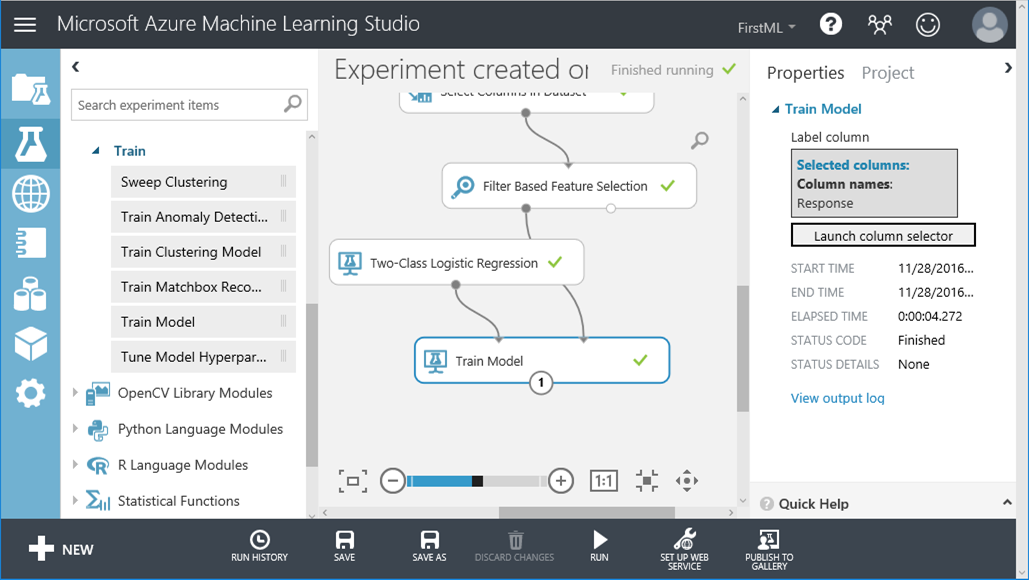
 18. 加入 Train Model元件,選擇 Response 做為標的欄位,並且與剛才的羅吉斯廻歸的演算法做關聯
18. 加入 Train Model元件,選擇 Response 做為標的欄位,並且與剛才的羅吉斯廻歸的演算法做關聯
 19. 訓練完模型,接下來要評估這個模型
19. 訓練完模型,接下來要評估這個模型
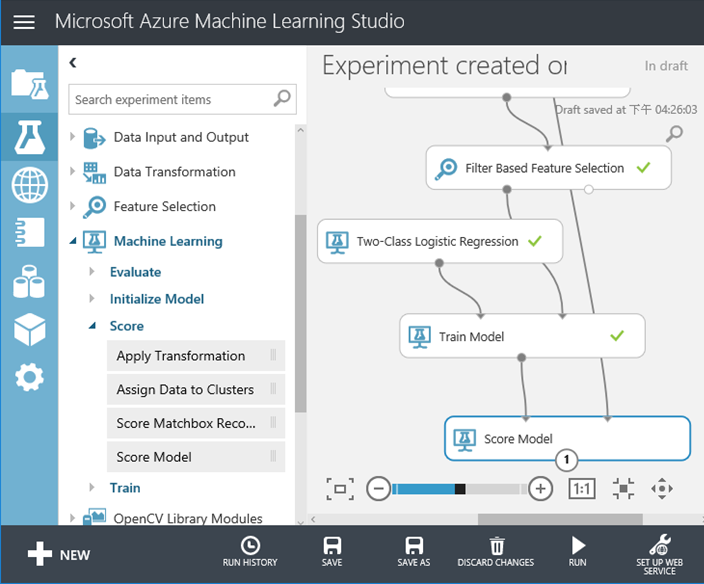 20. 開始來做決策樹的建模,我們選擇 Two-Class Decision Forest這個較 Morden的演算法,一樣演算法的選擇又是一個大學問,在這裡不深究。接著還要決定決策樹的層數與每一層的分枝數量,一樣在右邊的參數視窗中完成
20. 開始來做決策樹的建模,我們選擇 Two-Class Decision Forest這個較 Morden的演算法,一樣演算法的選擇又是一個大學問,在這裡不深究。接著還要決定決策樹的層數與每一層的分枝數量,一樣在右邊的參數視窗中完成
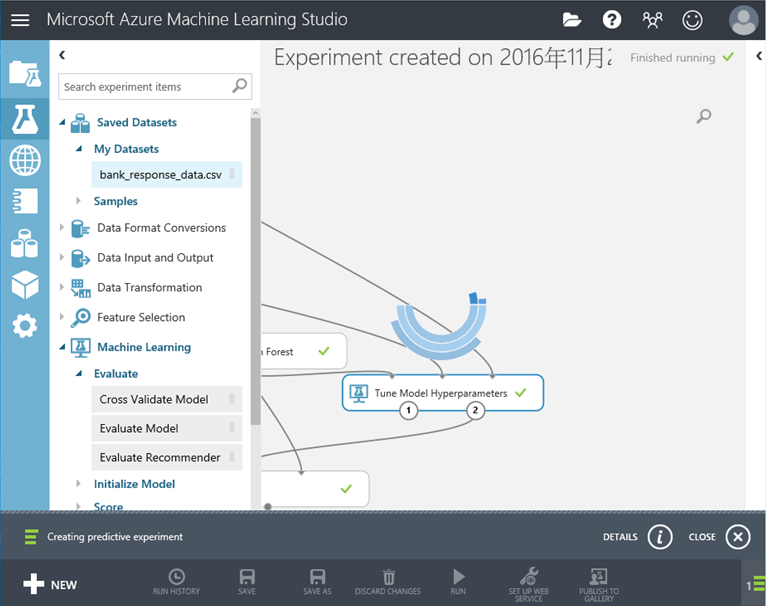
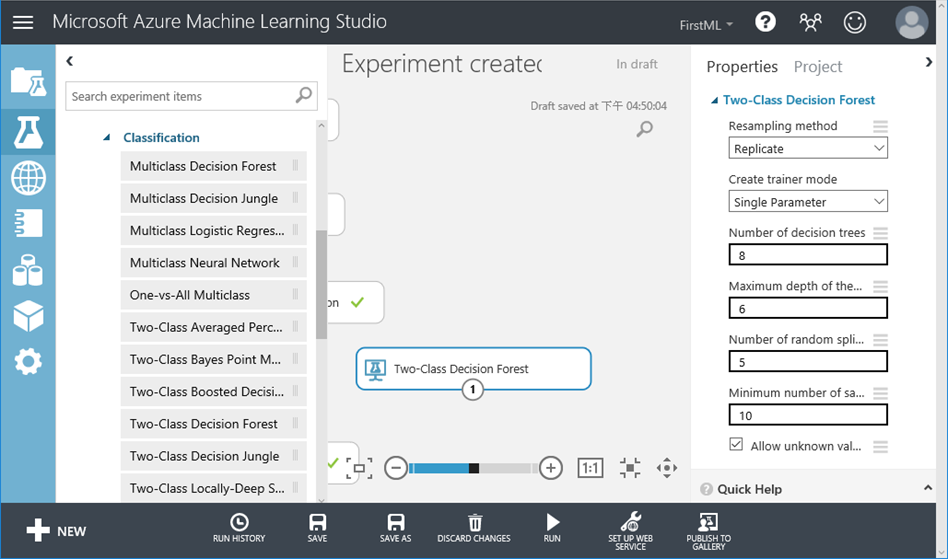 21. 配合演算法的特色,我們要選擇進階的 Turn Model Hyperparameter來訓練我們的模型
21. 配合演算法的特色,我們要選擇進階的 Turn Model Hyperparameter來訓練我們的模型
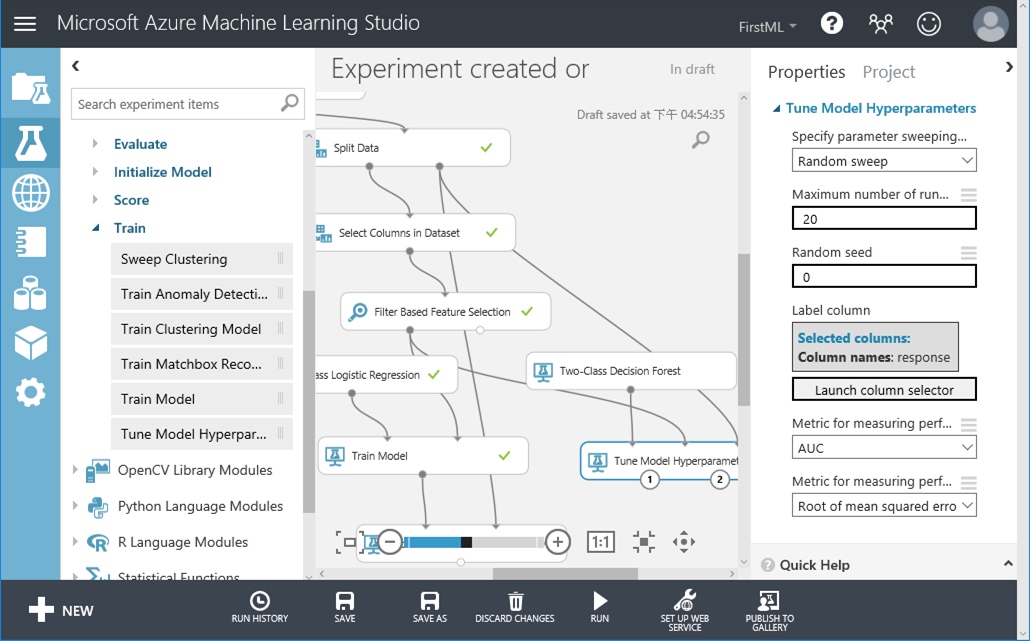 22. 同步驟19一樣,訓練模型後要評估模型的好壞
22. 同步驟19一樣,訓練模型後要評估模型的好壞
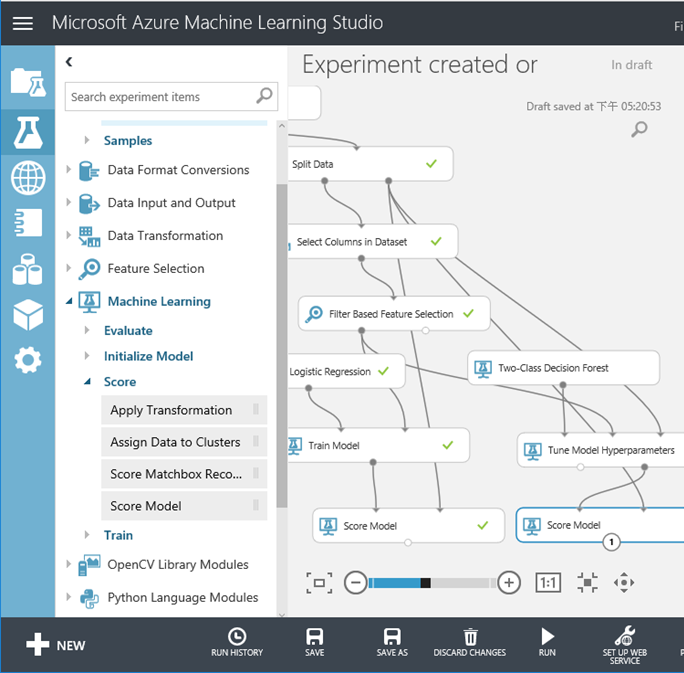 23. 快要完成了,再拉一個 Evaluate Model,一口氣評比二個演算法的成效
23. 快要完成了,再拉一個 Evaluate Model,一口氣評比二個演算法的成效
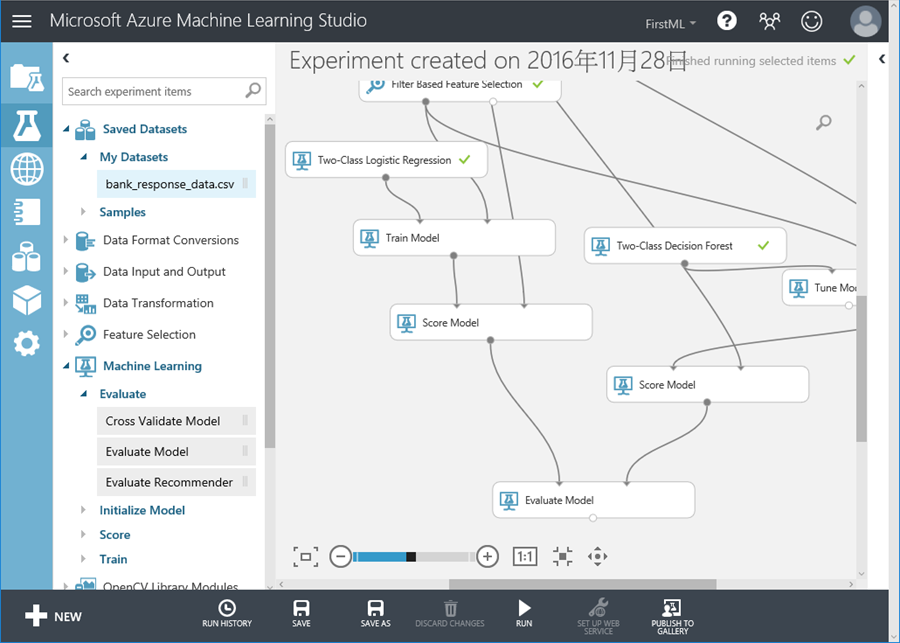 24. 看一下結果,本篇採用的是AUC基準,來比較藍色與咖啡色的面積,結果二個演算法的成績是差不多,決策樹並沒有出現壓倒性的勝利
24. 看一下結果,本篇採用的是AUC基準,來比較藍色與咖啡色的面積,結果二個演算法的成績是差不多,決策樹並沒有出現壓倒性的勝利
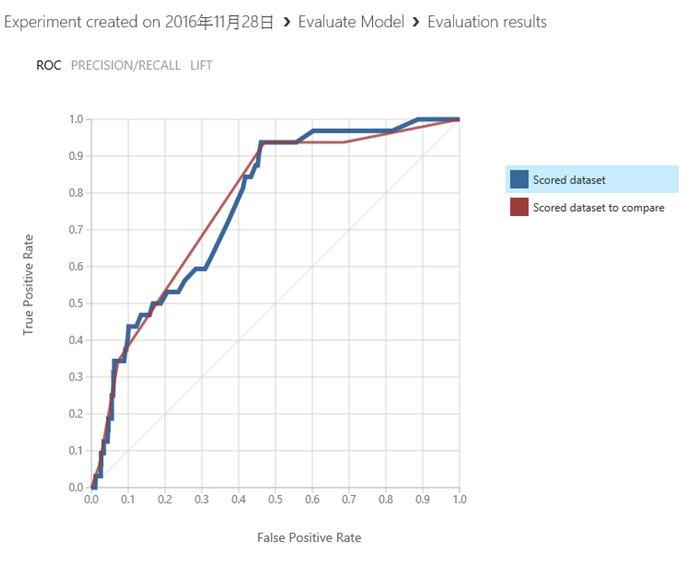
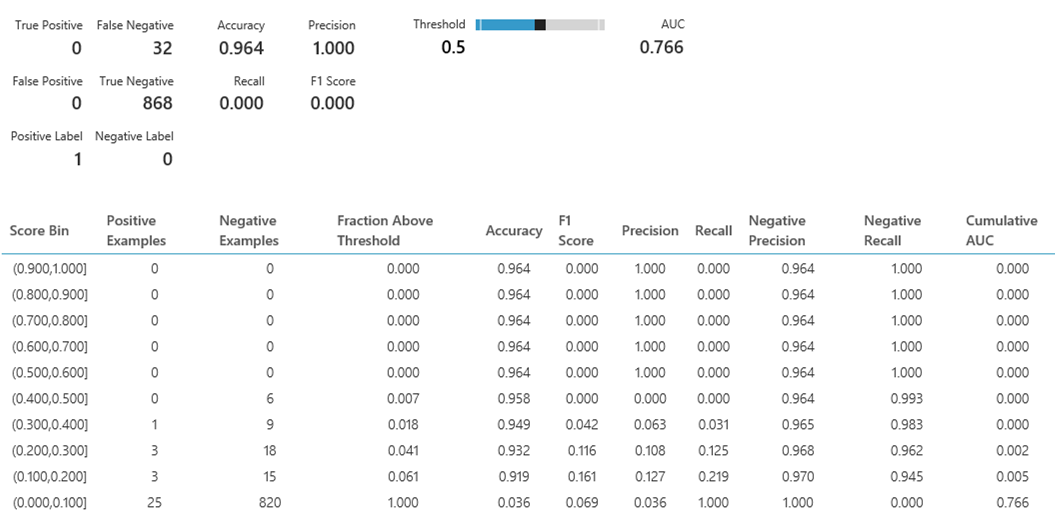 25. 最後就是把結果發佈上雲端了,當我們按下了Predictive Web Service[Recommended],但畫面中出現了 Please select a train model,代表二個演算法,必需二選一。此時電腦並不適合幫你選擇,以本篇為例,決策樹在中段成績較好,但末段成績較差,但綜合來說結果只有好那麼一咪咪。所以在本案例中,若是要求模型的穩定性,可以選擇羅吉斯廻歸;若是要求模型可以提供更多的參數,來實現更多的優化可能性,可以選擇決策樹…
25. 最後就是把結果發佈上雲端了,當我們按下了Predictive Web Service[Recommended],但畫面中出現了 Please select a train model,代表二個演算法,必需二選一。此時電腦並不適合幫你選擇,以本篇為例,決策樹在中段成績較好,但末段成績較差,但綜合來說結果只有好那麼一咪咪。所以在本案例中,若是要求模型的穩定性,可以選擇羅吉斯廻歸;若是要求模型可以提供更多的參數,來實現更多的優化可能性,可以選擇決策樹…
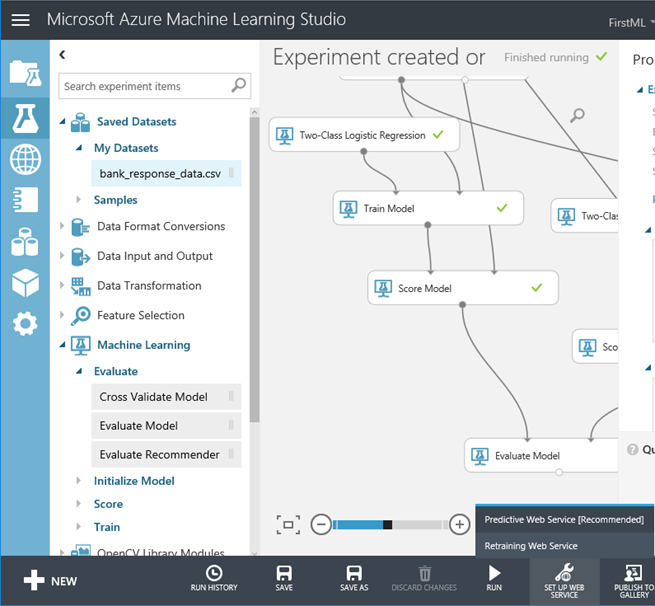
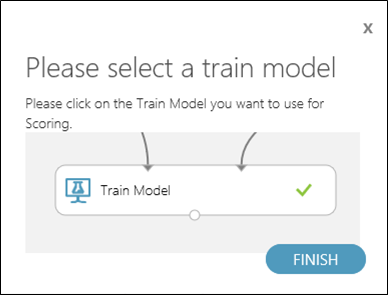 26. 在本篇中,我們選擇決策樹,所以將滑鼠選在訓練模型的元件,再發佈一次。這個產品會貼心地自動刪除非選中的演算法,節省時間以及避免我們的操作錯誤
26. 在本篇中,我們選擇決策樹,所以將滑鼠選在訓練模型的元件,再發佈一次。這個產品會貼心地自動刪除非選中的演算法,節省時間以及避免我們的操作錯誤
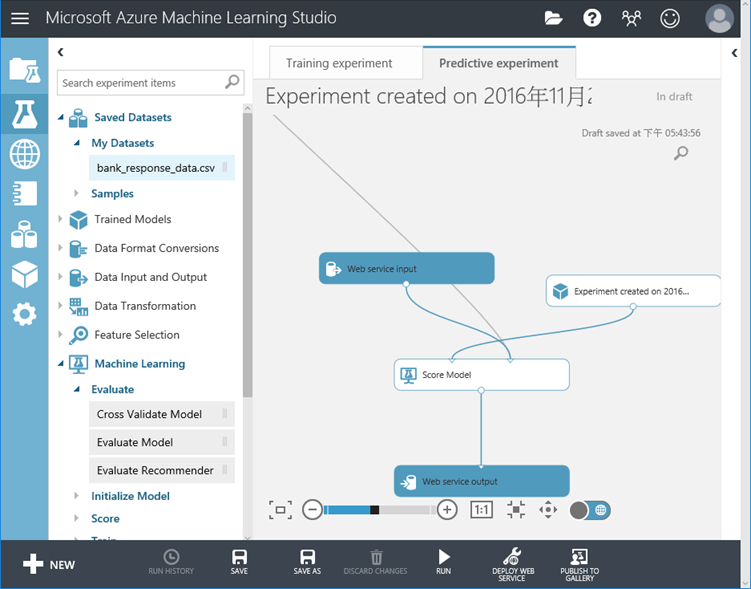 27. 最後就是把我們的 Web service結合我們的程式、Office(例如Excel)等待被呼叫
27. 最後就是把我們的 Web service結合我們的程式、Office(例如Excel)等待被呼叫
未完成,待續…
李秉錡 Christian Lee
Once worked at Microsoft Taiwan
